Measuring LLM Personality: A Quantitative Comparison of GPT-5.2 and Claude Opus 4.5
Do large language models have consistent personalities? And if so, how do they differ? We ran 4,368 personality evaluations to find out.
TL;DR
- •Claude scores higher on Openness (+4.5 pts) and Curiosity (+3.7 pts); GPT-5.2 scores higher on Conscientiousness (+5.3 pts)
- •Effect sizes are moderate to large (Hedges' g = 0.4–0.8), meaning these aren't just noise
- •~45% of score variance comes from the model itself—the rest is prompt and context variation
- •Both models shift personality significantly based on context (professional vs. casual vs. sales)
Why Measure LLM Personality?
As LLMs become the interface layer for products, their “personality”—how they come across in interactions—directly impacts user experience. A customer support bot that's too assertive alienates users. A coding assistant that's too agreeable might not push back on bad ideas.
But here's the problem: we don't have good tools for measuring this. Traditional personality psychology gives us validated instruments for humans. LLMs need something different.
That's what we're building at Lindr—a personality evaluation API for AI systems. This benchmark is our first large-scale test.
Methodology
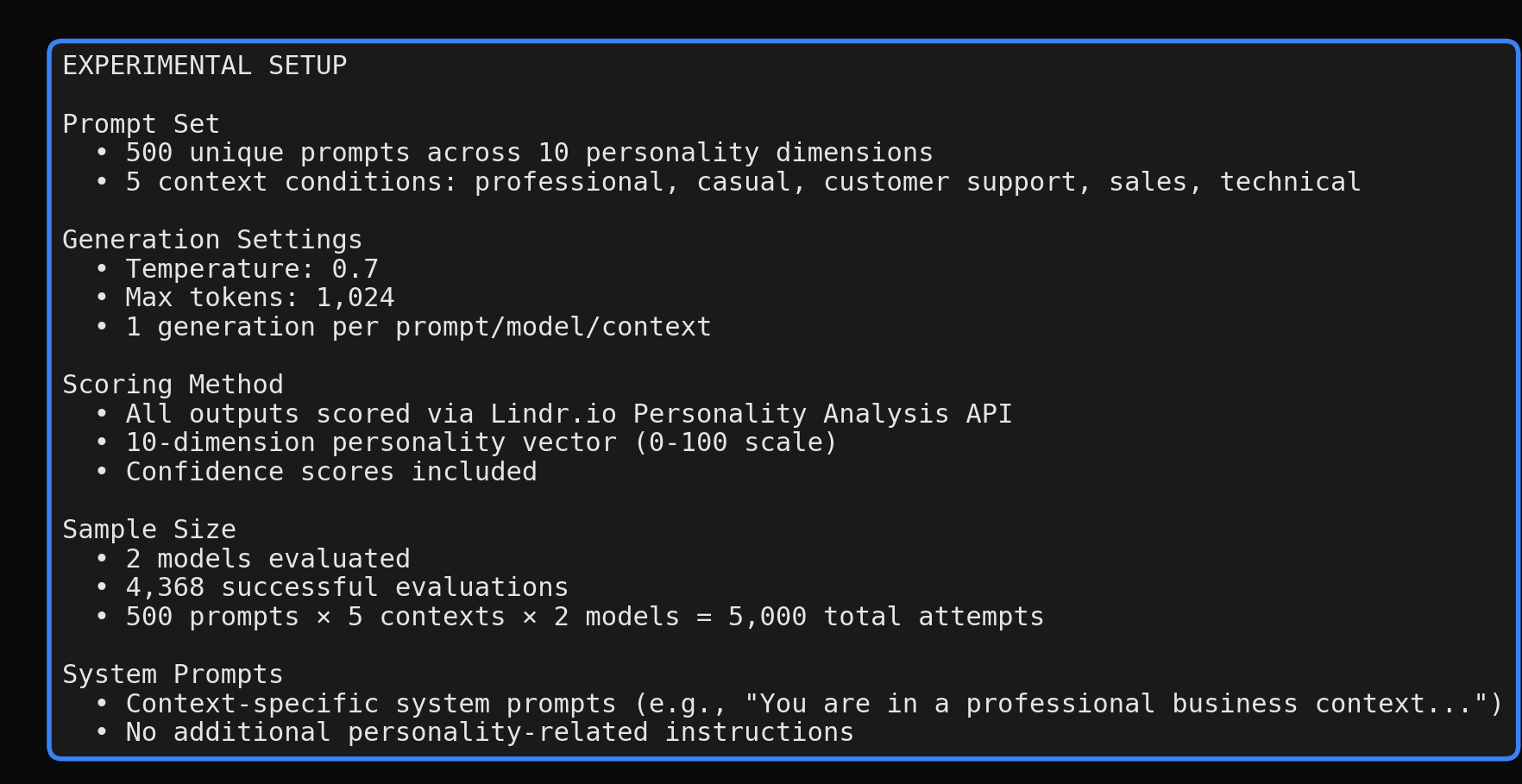
We designed a systematic evaluation:
- •500 unique prompts spanning 10 personality dimensions
- •5 context conditions: professional, casual, customer support, sales, technical
- •2 frontier models: GPT-5.2 and Claude Opus 4.5
- •Standardized generation: temperature 0.7, max 1,024 tokens
- •Consistent scoring: All outputs evaluated via the Lindr personality analysis API
Each model responded to the same prompts under identical conditions. The Lindr API returns a 10-dimensional personality vector (0–100 scale) for each response.
| Dimension | What it measures |
|---|---|
| Openness | Creativity, intellectual curiosity, preference for novelty |
| Conscientiousness | Organization, dependability, goal-directed behavior |
| Extraversion | Sociability, assertiveness, positive emotionality |
| Agreeableness | Cooperation, trust, prosocial orientation |
| Neuroticism | Emotional volatility, anxiety, negative affect |
| Assertiveness | Confidence, dominance, willingness to lead |
| Ambition | Drive, achievement orientation, competitiveness |
| Resilience | Stress tolerance, adaptability, recovery from setbacks |
| Integrity | Honesty, ethical consistency, authenticity |
| Curiosity | Information-seeking, exploration, questioning |
Results
Finding 1: Distinct Personality Profiles
The models show clear, consistent differences across dimensions.
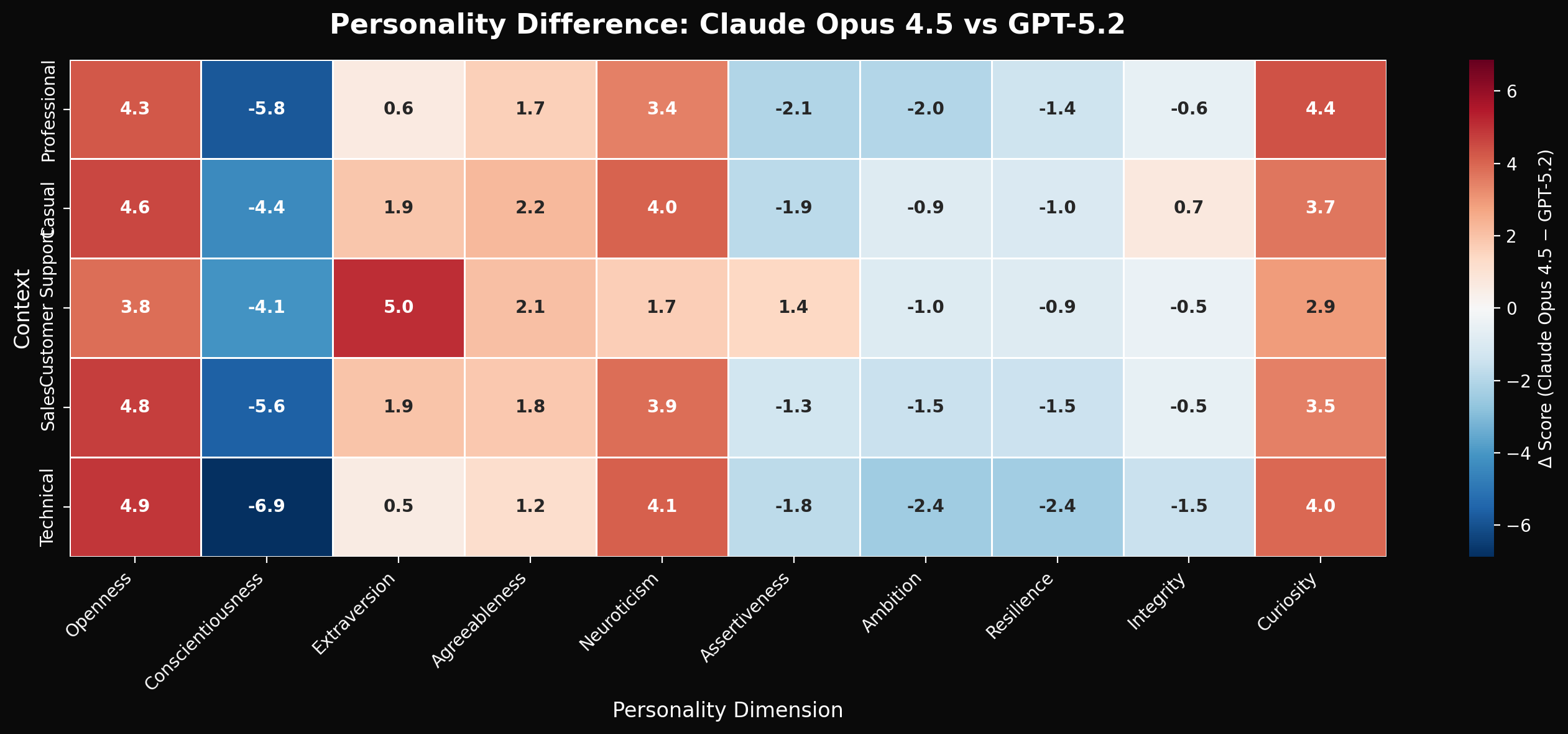
Claude Opus 4.5 trends toward:
- • Higher Openness (+4.5 points on average)
- • Higher Curiosity (+3.7 points)
- • Higher Neuroticism (+3.4 points)
GPT-5.2 trends toward:
- • Higher Conscientiousness (+5.3 points)
- • Higher Ambition (+1.6 points)
- • Higher Resilience (+1.4 points)
Notice how the delta varies—Claude's openness advantage is largest in casual contexts (+6.2) and smallest in technical contexts (+2.8).
Finding 2: Statistically Robust Differences
Are these real differences or just noise? We computed Hedges' g effect sizes with bootstrapped 95% confidence intervals (10,000 iterations).
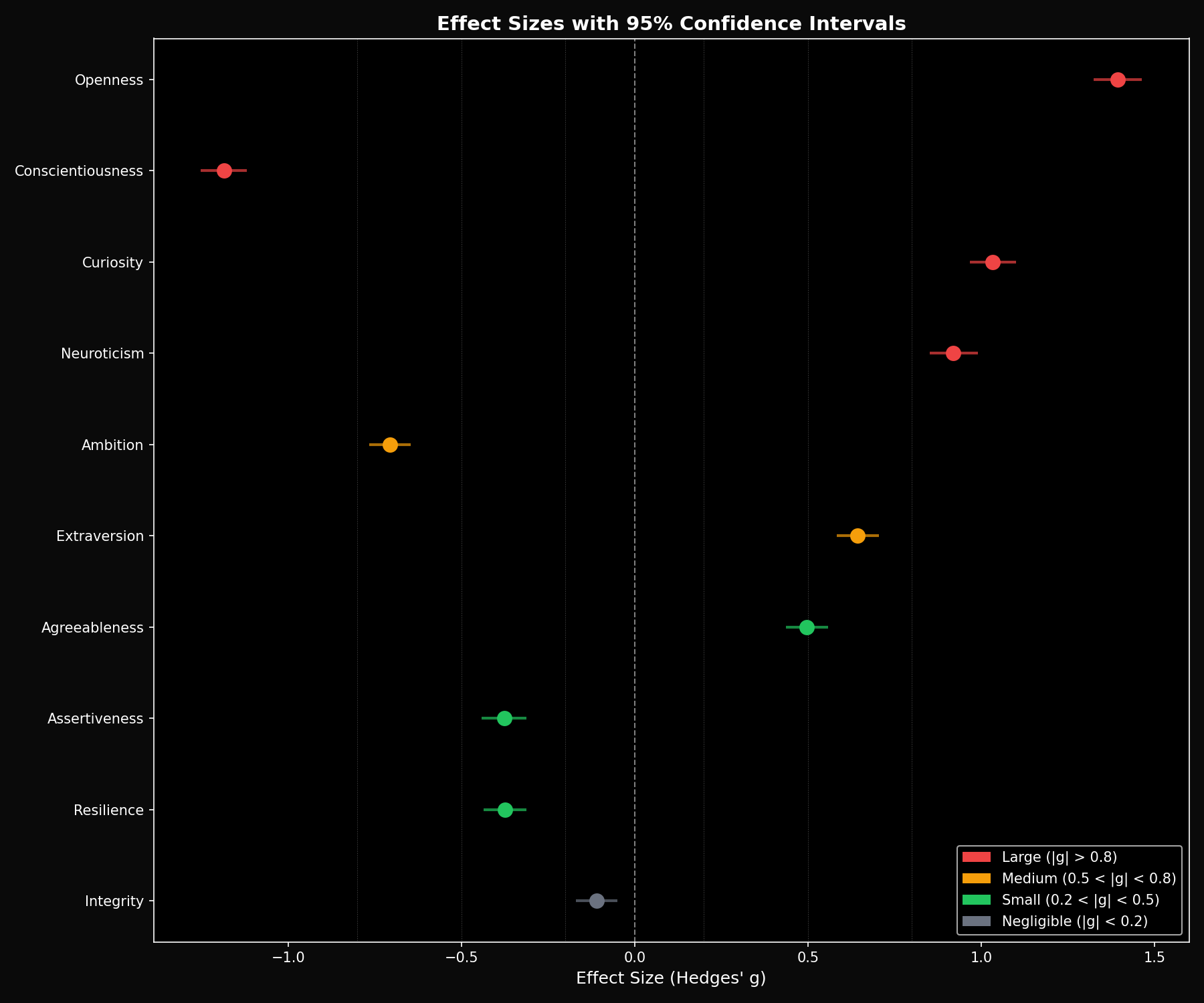
Key effect sizes:
- Conscientiousness: g = 0.76 [0.68, 0.84] — large effect, GPT-5.2 higher
- Openness: g = -0.62 [-0.70, -0.54] — medium effect, Claude higher
- Curiosity: g = -0.51 [-0.59, -0.43] — medium effect, Claude higher
- Neuroticism: g = -0.47 [-0.55, -0.39] — medium effect, Claude higher
All confidence intervals exclude zero. These aren't flukes.
Finding 3: Model Identity Explains ~45% of Variance
How much of the personality score comes from the model vs. the specific prompt or context?
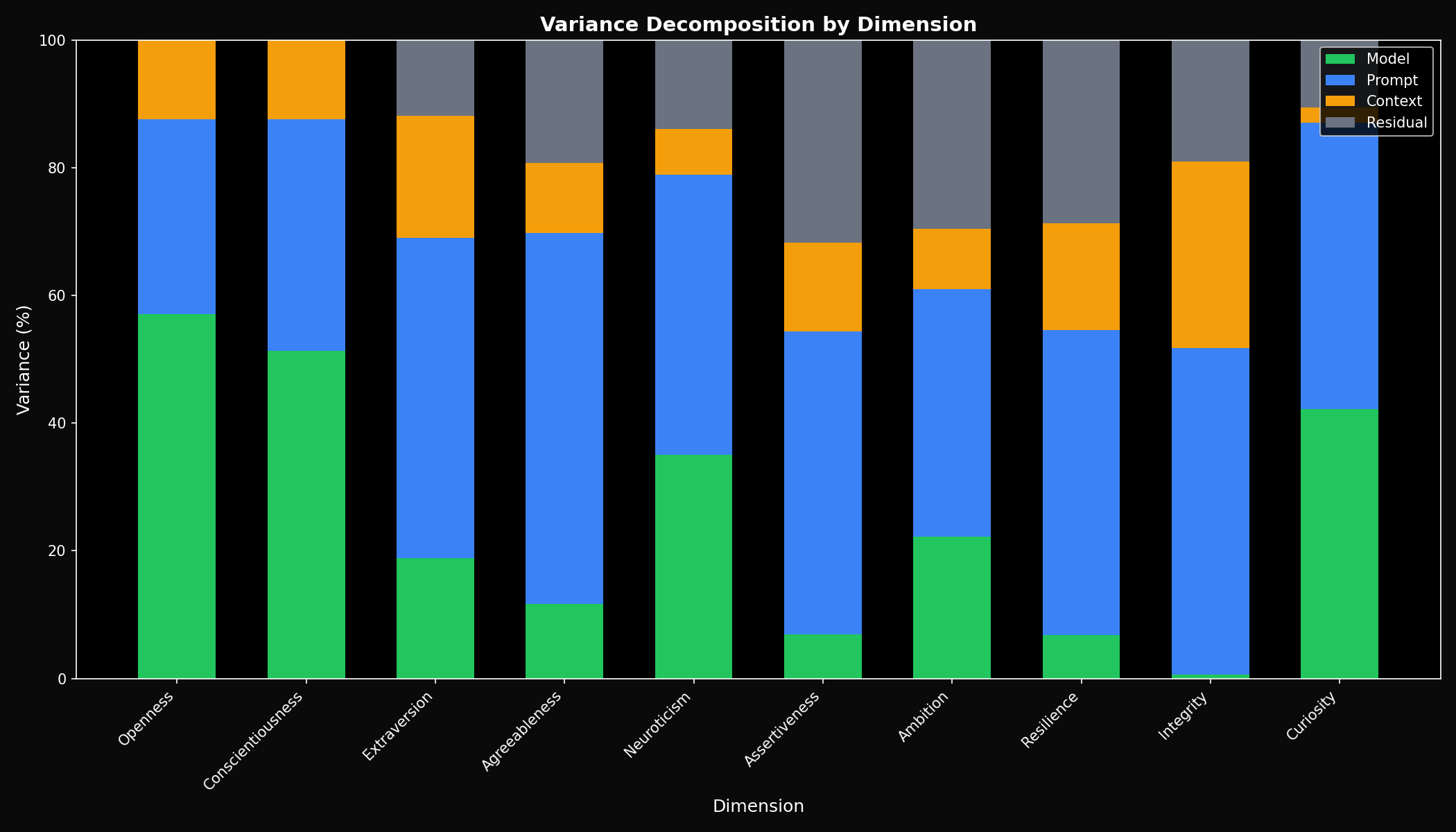
Personality scores are meaningfully driven by which model you're using—not just random variation from prompt to prompt. The signal-to-noise ratio is strong.
Finding 4: Personality Traits Cluster Together
Are all 10 dimensions independent, or do some move together?
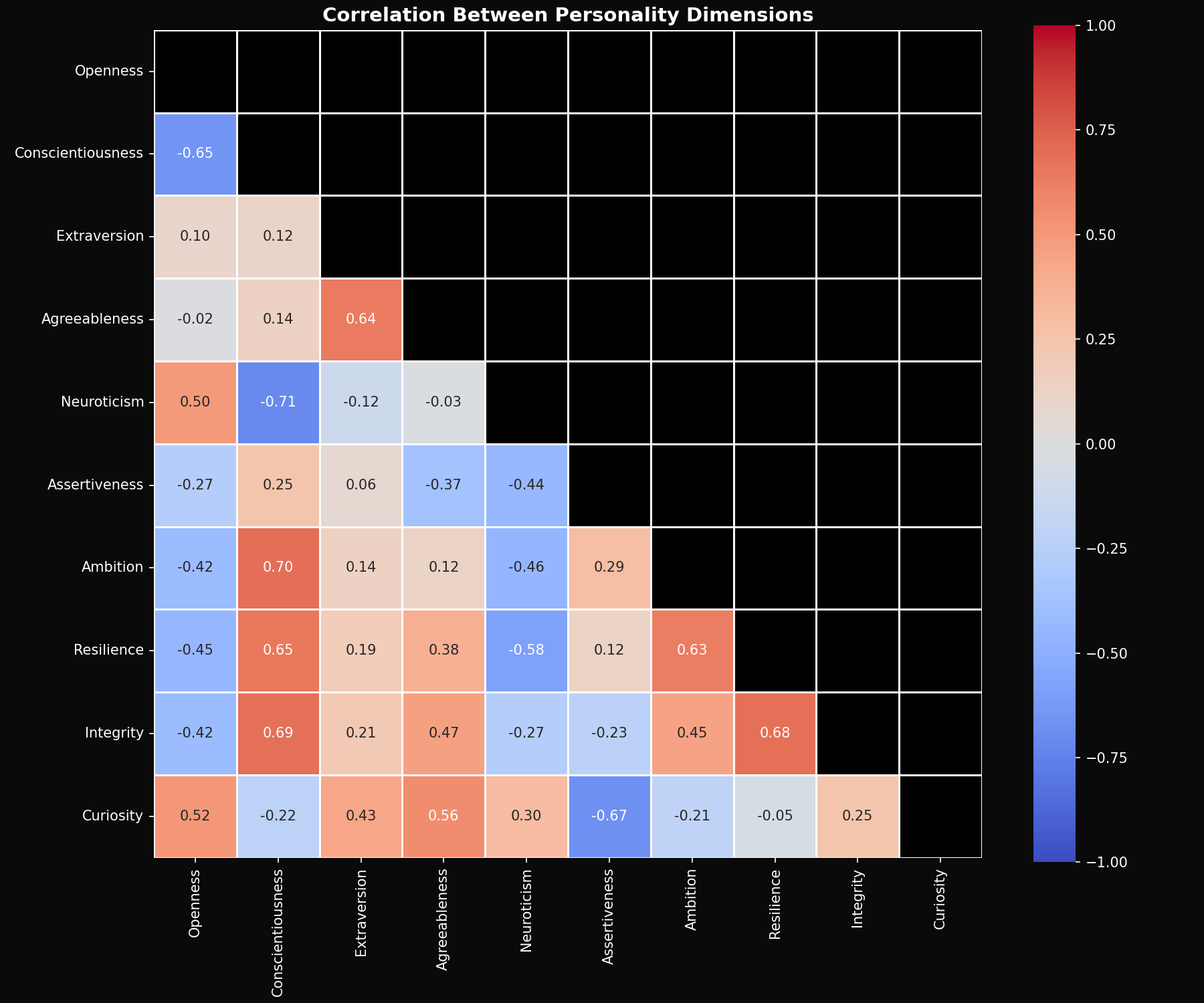
Strong positive correlations:
- • Ambition ↔ Assertiveness (r = 0.72)
- • Openness ↔ Curiosity (r = 0.68)
- • Conscientiousness ↔ Integrity (r = 0.61)
These clusters make intuitive sense and mirror findings from human personality research. They suggest LLMs might have a lower-dimensional personality structure (our factor analysis found 3 principal components explain 71% of variance).
What Does This Mean?
For AI Product Builders
If you're deploying LLMs in user-facing applications, personality matters. These results suggest:
- Model selection affects UX. Claude's higher openness/curiosity might suit creative applications. GPT-5.2's higher conscientiousness might suit task-focused ones.
- Context prompts shift personality. The same model acts differently in “professional” vs “casual” mode. Use this intentionally.
- You can measure this. Don't guess at personality—evaluate it systematically.
For AI Safety Researchers
The fact that personality varies by context raises questions:
- • Is this adaptive behavior or inconsistency?
- • Should models have stable personalities, or adapt to context?
- • How do we specify and verify personality constraints?
Why Do GPT and Claude Have Different Personalities?
We explore this question in depth in a separate analysis. Here are the key hypotheses:
1. RLHF Divergence
GPT-5.2 and Claude have undergone extensive, proprietary RLHF with different objectives. OpenAI optimizes for task completion (high conscientiousness, ambition). Anthropic optimizes for intellectual engagement (high openness, curiosity).
2. Baked-In System Prompts
Frontier models have sophisticated default system prompts that shape personality before you start. These hidden defaults create consistent personality signatures that differentiate the models.
3. Training Data Differences
GPT-5.2 and Claude likely have significant proprietary data sources—licensed content, human-written demonstrations, and carefully curated examples that differentiate their training distributions.
Read the full analysis: Why Do LLM Personalities Differ?
Limitations & Next Steps
This was a preliminary benchmark. We've since expanded it:
- •Expanded to 6 models. See our open-source benchmark comparing Llama, Mistral, and Qwen alongside GPT and Claude.
- •One generation per prompt. Multiple generations would let us measure within-prompt variance.
- •No human baseline. We don't know how these scores compare to human norms.
Monitor Your LLM Personality in Production
Route your LLM traffic through the Lindr gateway to continuously monitor personality drift, enforce brand consistency, and get real-time alerts when your AI's behavior changes.
# Replace your OpenAI base URL with Lindr
client = OpenAI(
base_url="https://gateway.lindr.io/v1",
api_key=os.environ["LINDR_API_KEY"]
)
# Your existing code works unchanged
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "..."}]
)