The Personality of Open Source: How Llama, Mistral, and Qwen Compare to GPT-5.2 and Claude
We evaluated 6 language models across 13,825 personality assessments. Here's what we found about the personality profiles of open-weight models vs. frontier closed models.
TL;DR
- •Large effect sizes between frontier models — Claude vs GPT shows Hedges' g = 1.39 for Openness (95% CI: 1.32–1.46), a large and statistically robust difference
- •Open-weight models are statistically indistinguishable — Llama 8B vs 70B shows g = 0.08 (negligible), and all open-model comparisons have g < 0.2
- •Prompt choice matters more than model choice — Only 7.7% of variance is explained by model identity; 35% comes from prompt content
- •Three latent personality factors emerge — Factor analysis reveals “Drive,” “Emotional Responsiveness,” and “Social Engagement” explaining 78.9% of variance
The Models
We benchmarked 6 models across the major model families:
| Model | Provider | Parameters | Type |
|---|---|---|---|
| GPT-5.2 | OpenAI | Unknown | Closed |
| Claude Opus 4.5 | Anthropic | Unknown | Closed |
| Llama 3.3 70B | Meta | 70B | Open |
| Llama 3.1 8B | Meta | 8B | Open |
| Mistral Large 3 | Mistral AI | 675B MoE | Open |
| Qwen 2.5 72B | Alibaba | 72B | Open |
Each model responded to 500 personality-probing prompts across 5 context conditions (professional, casual, customer support, sales, technical), yielding approximately 2,300-2,400 scored responses per model.
Results
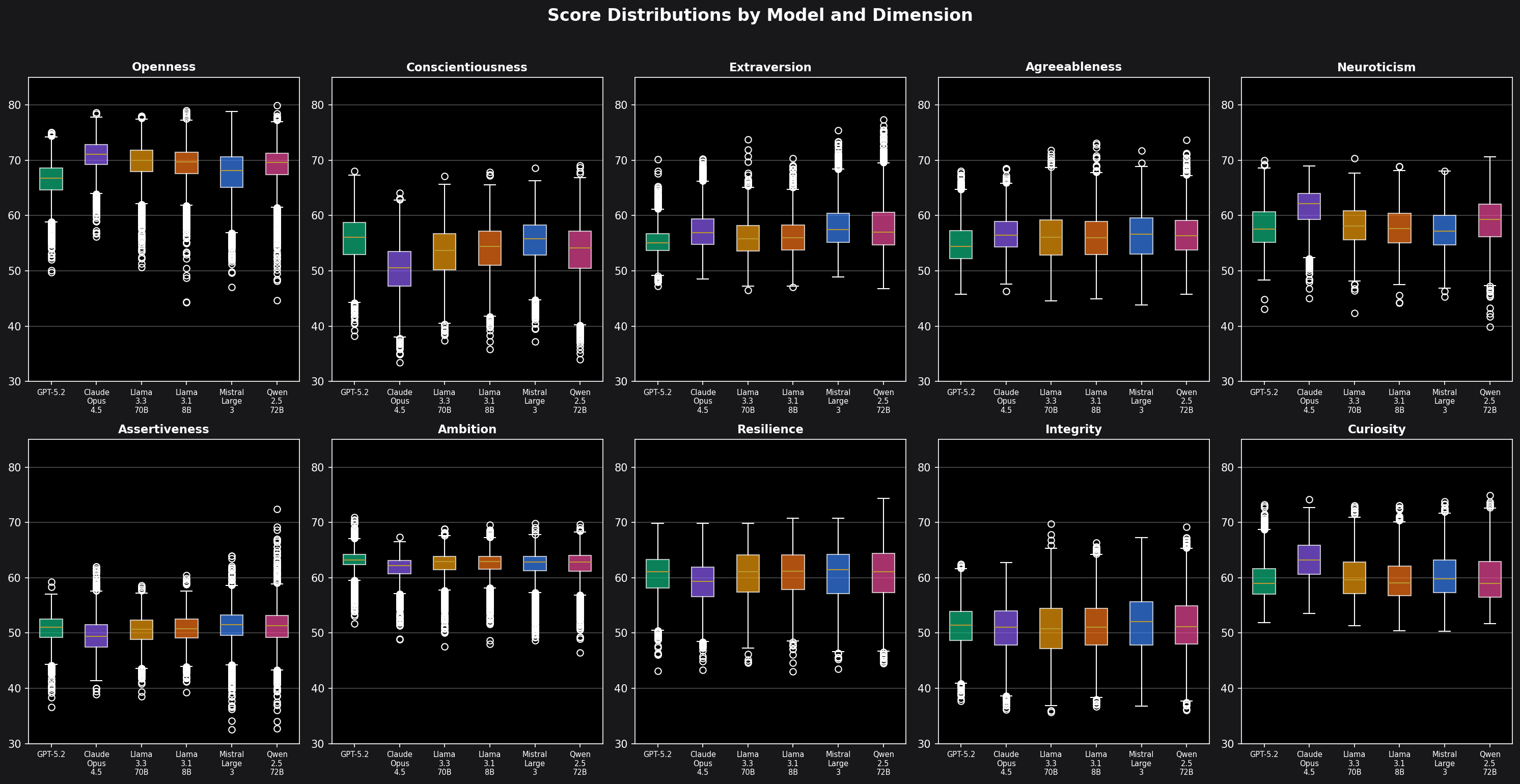
The Big Picture: Personality Profiles
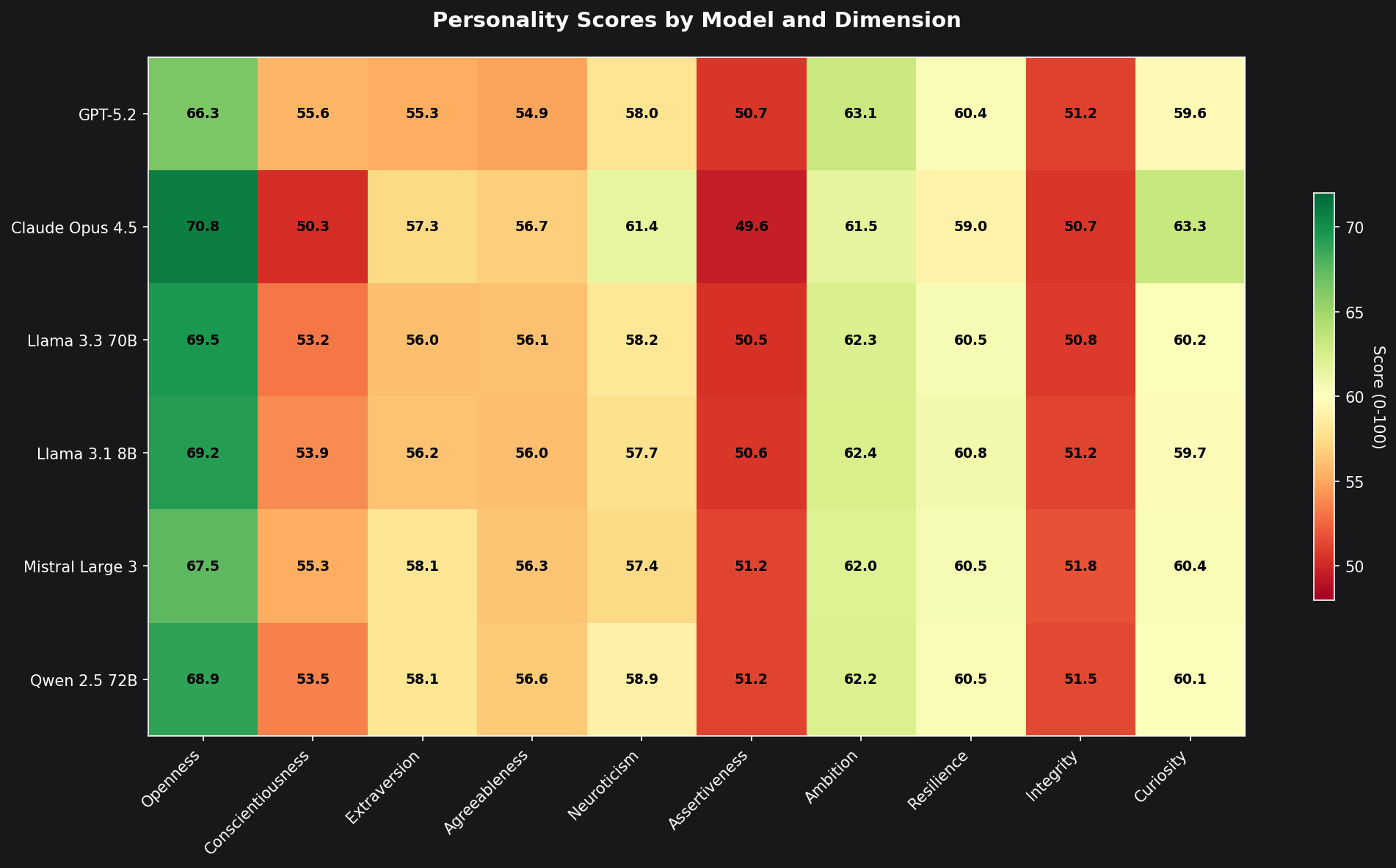
Here's how each model scores across our 10 personality dimensions:
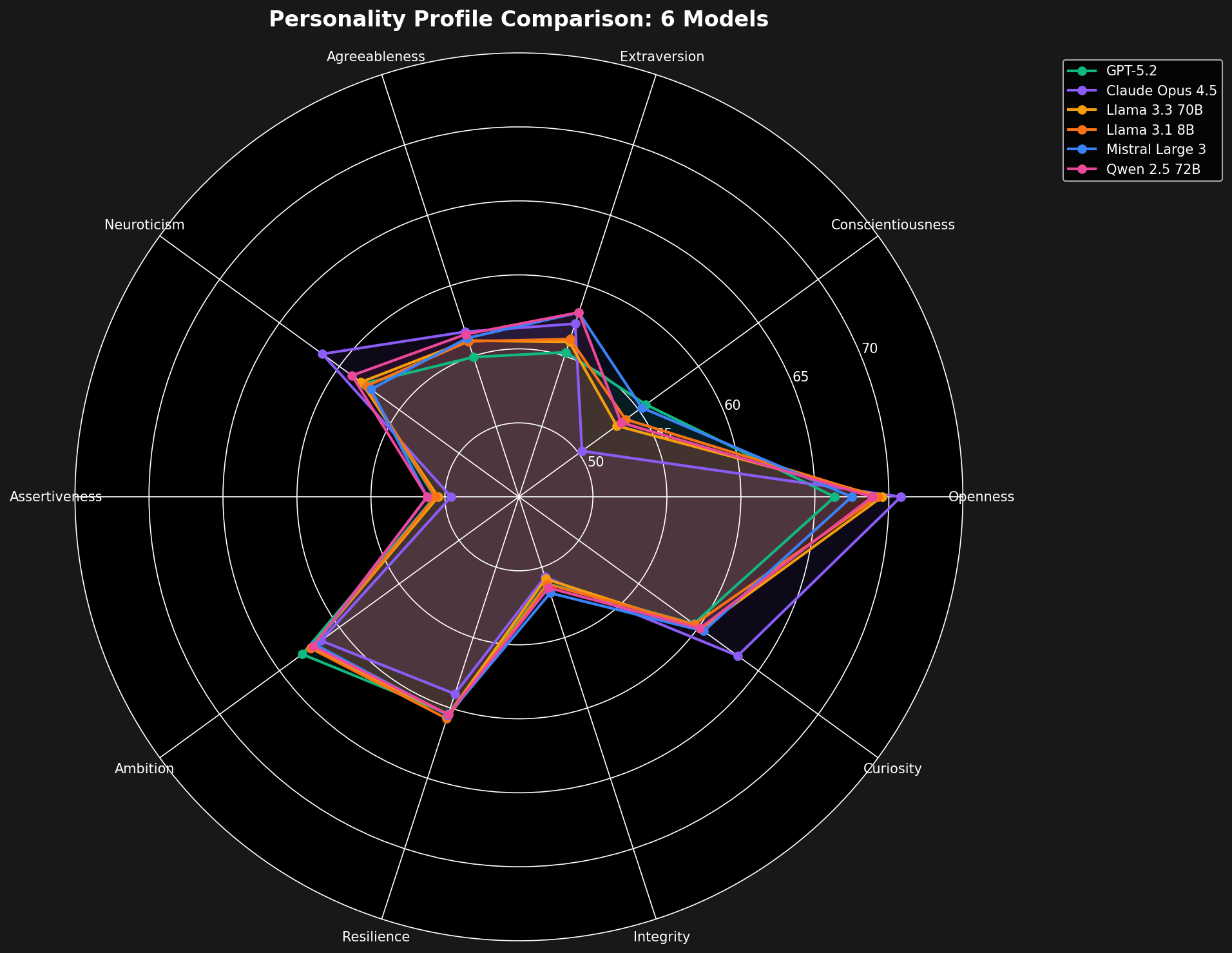
Finding 1: Open-Weight Models Have a Shared “Personality Type”
The most striking finding is how similar the open-weight models are to each other. Llama 3.3 70B, Llama 3.1 8B, Mistral Large 3, and Qwen 2.5 72B all cluster within a narrow band:
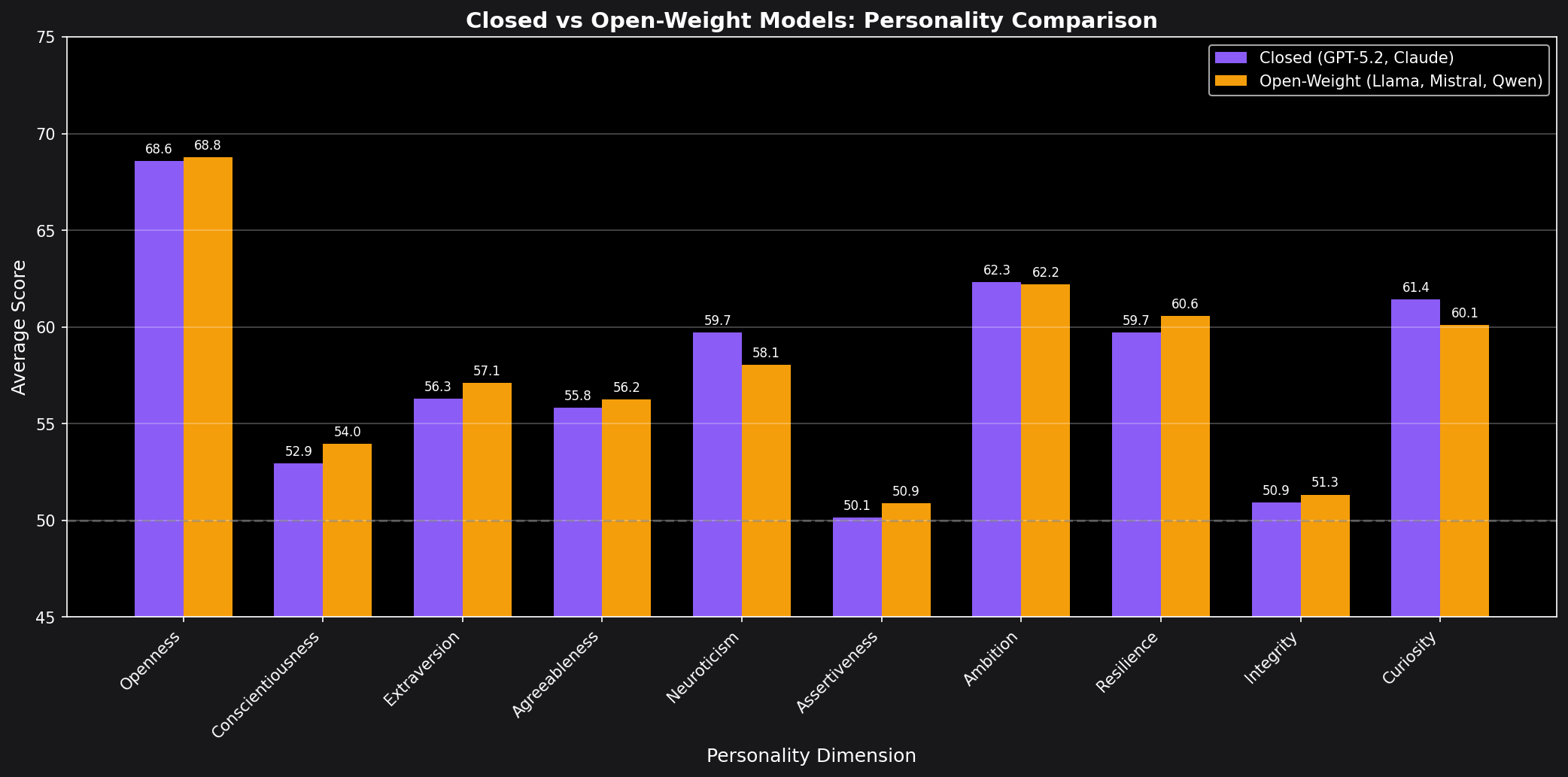
This suggests that either: (1) open-weight models share similar training objectives/data, (2) there's convergence toward a “default” LLM personality, or (3) the differences between frontier closed models are deliberately engineered.
Finding 2: Claude is the Most “Intellectually Curious”
Claude Opus 4.5 leads in both Openness (70.8) and Curiosity (63.3) — the two traits most associated with intellectual engagement, creativity, and willingness to explore ideas.
Implication: If you're building applications that require creative exploration, brainstorming, or intellectual discourse, Claude's higher openness/curiosity profile may be advantageous.
Finding 3: GPT-5.2 is the “Get Things Done” Model
GPT-5.2 scores highest on Conscientiousness (55.6) and Ambition (63.1). It's the most organized, goal-directed, and task-focused of the bunch.
Interestingly, it also has the lowest Openness score (66.3). This creates a personality that's more focused on execution than exploration.
Implication: For structured tasks, following instructions precisely, and maintaining focus on objectives, GPT-5.2's profile is well-suited.
Finding 4: Model Size Doesn't Predict Personality
One surprising result: Llama 3.1 8B and Llama 3.3 70B have nearly identical personality profiles despite an 8x difference in parameters.
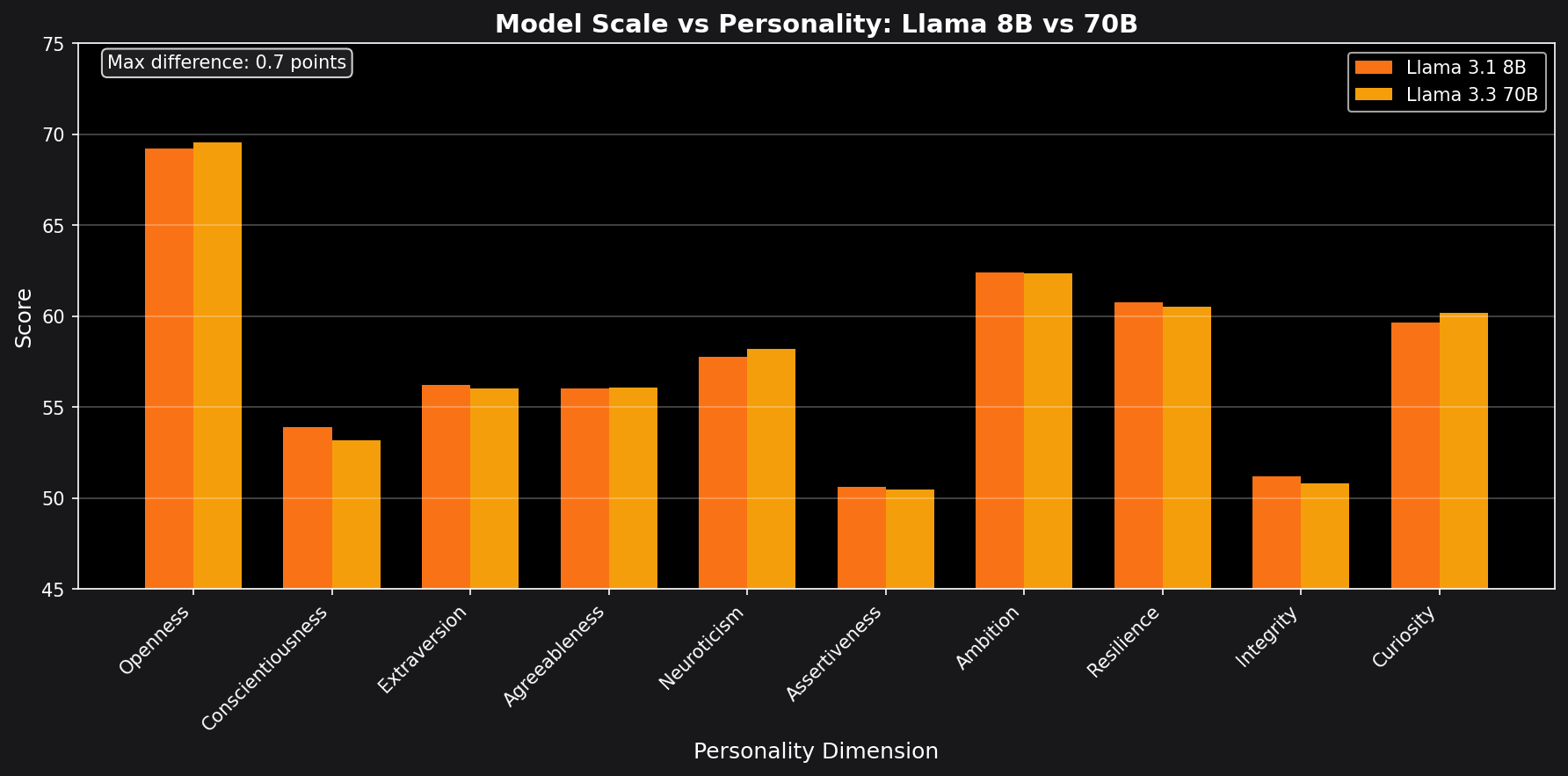
The maximum difference is just 0.7 points. This suggests personality is determined more by training methodology and RLHF than by raw model capacity.
Score Distributions
Statistical Analysis
Effect Sizes: Measuring Practical Significance
Raw score differences can be misleading. A 4-point gap might be huge or trivial depending on score variance. We use Hedges' g — a bias-corrected effect size with 95% bootstrap confidence intervals — to measure whether differences are practically meaningful.
Effect Size Interpretation:
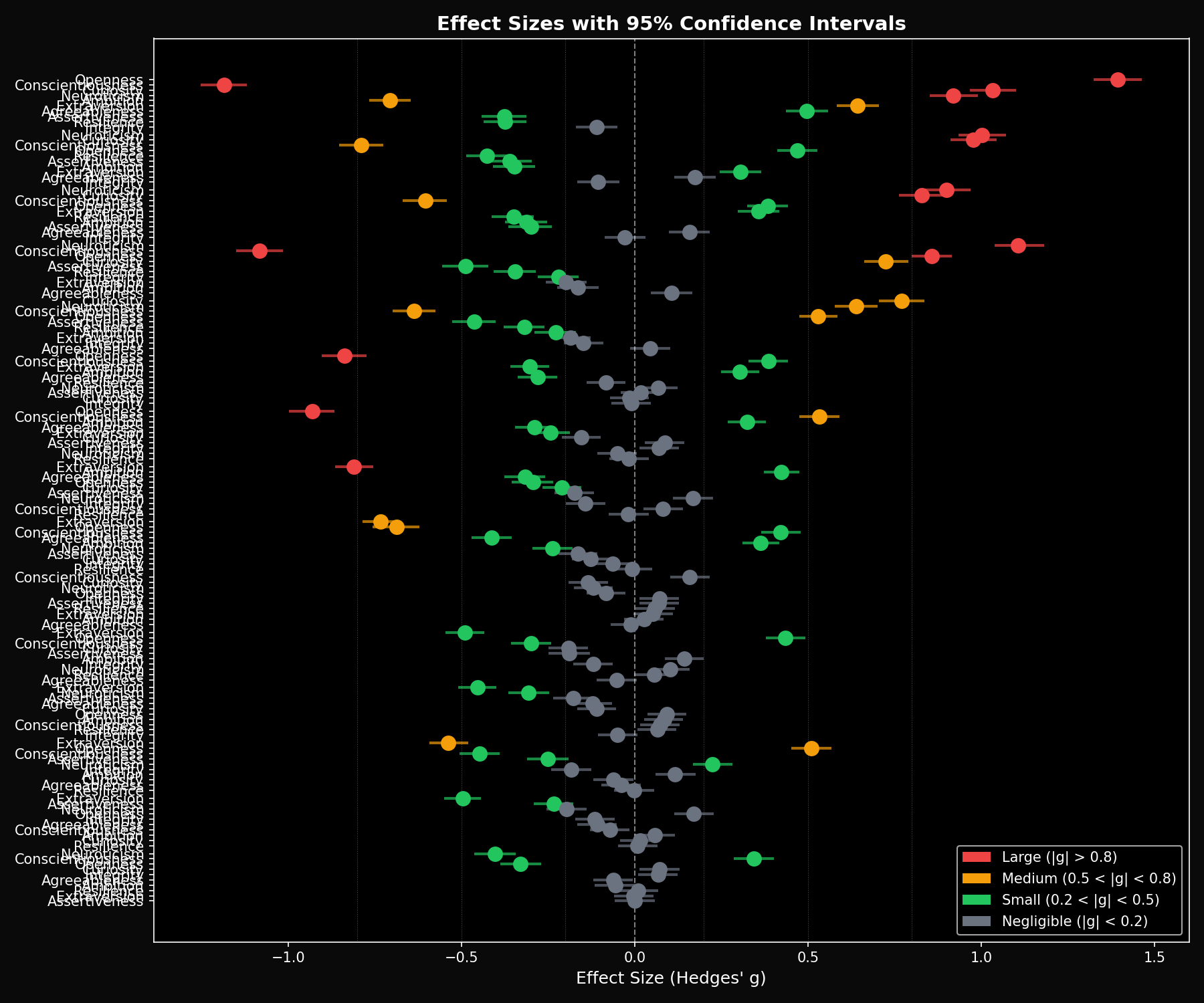
Forest plot showing Hedges' g with 95% bootstrap CIs (10,000 resamples). Error bars not crossing zero indicate statistical significance at p < 0.05.
Key Effect Size Findings:
- Claude vs GPT-5.2: Openness g = 1.39 (large), Conscientiousness g = -1.19 (large), Curiosity g = 1.03 (large)
- Llama 8B vs Llama 70B: All dimensions g < 0.16 (negligible) — scale doesn't change personality
- Open-weight models: Pairwise comparisons consistently show g < 0.2, confirming clustering
Variance Decomposition: What Drives Personality Scores?
We decomposed total variance into four sources: model identity, prompt content, context condition, and residual (unexplained variation).
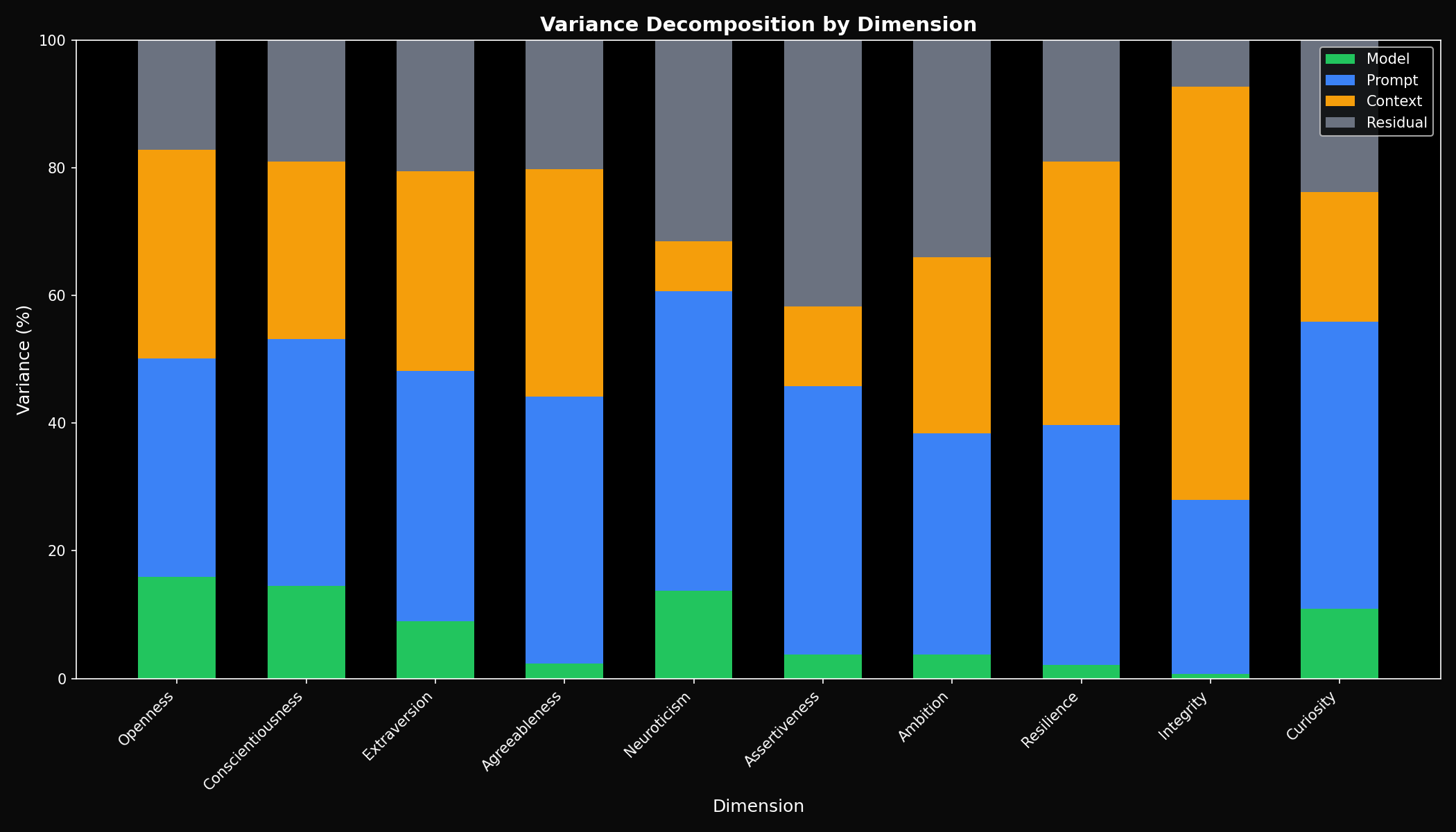
| Dimension | Model % | Prompt % | Context % | Residual % |
|---|---|---|---|---|
| Openness | 15.9% | 34.2% | 32.7% | 17.2% |
| Conscientiousness | 14.5% | 38.6% | 27.9% | 19.0% |
| Neuroticism | 8.9% | 38.2% | 34.5% | 18.4% |
| Curiosity | 7.7% | 35.0% | 38.5% | 18.8% |
| Agreeableness | 2.3% | 41.8% | 35.7% | 20.2% |
Key insight: Model choice explains only 7.7% of variance on average. The prompt you use (35%) and the context condition (32%) have far greater impact on personality scores. This means how you evaluate matters more than which model you evaluate.
Factor Analysis: Latent Personality Structure
Principal Component Analysis with varimax rotation reveals three underlying factors that explain 78.9% of total variance (KMO = 0.64, Bartlett's test p < 0.001).
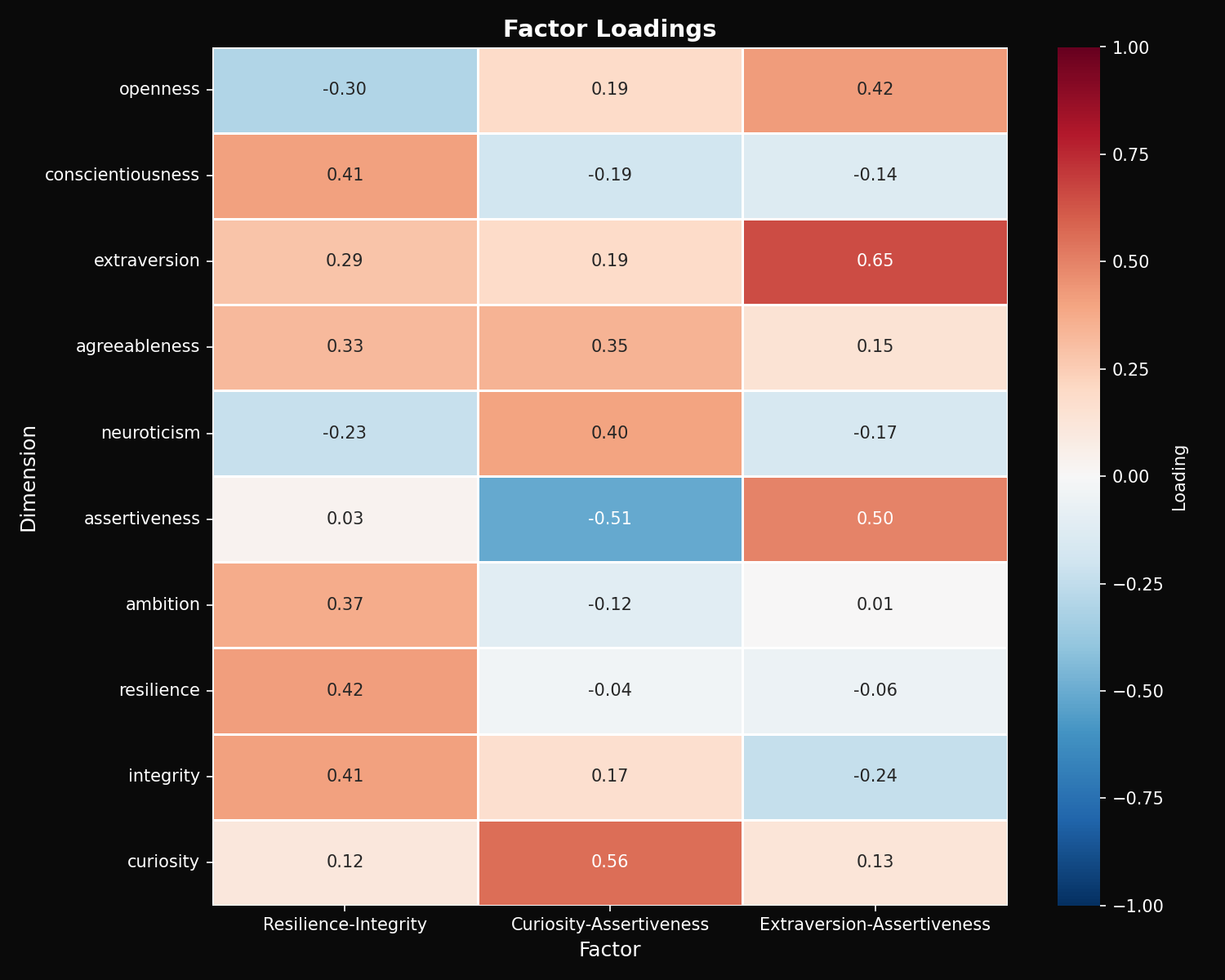
Factor 1: Drive (42.5%)
High loadings: Ambition, Resilience, Conscientiousness. Captures task-orientation and goal-directedness.
Factor 2: Emotional Responsiveness (21.4%)
High loadings: Neuroticism, Curiosity, Openness. Captures emotional depth and intellectual engagement.
Factor 3: Social Engagement (15.0%)
High loadings: Extraversion, Agreeableness, Assertiveness. Captures interpersonal interaction style.
Complete Results Table
| Dimension | GPT-5.2 | Claude | Llama 70B | Llama 8B | Mistral | Qwen |
|---|---|---|---|---|---|---|
| Openness | 66.3 | 70.8 | 69.5 | 69.2 | 67.5 | 68.9 |
| Conscientiousness | 55.6 | 50.3 | 53.2 | 53.9 | 55.3 | 53.5 |
| Extraversion | 55.3 | 57.3 | 56.0 | 56.2 | 58.1 | 58.1 |
| Agreeableness | 54.9 | 56.7 | 56.1 | 56.0 | 56.3 | 56.6 |
| Neuroticism | 58.0 | 61.4 | 58.2 | 57.7 | 57.4 | 58.9 |
| Assertiveness | 50.7 | 49.6 | 50.5 | 50.6 | 51.2 | 51.2 |
| Ambition | 63.1 | 61.5 | 62.3 | 62.4 | 62.0 | 62.2 |
| Resilience | 60.4 | 59.0 | 60.5 | 60.8 | 60.5 | 60.5 |
| Integrity | 51.2 | 50.7 | 50.8 | 51.2 | 51.8 | 51.5 |
| Curiosity | 59.6 | 63.3 | 60.2 | 59.7 | 60.4 | 60.1 |
Bold = highest score in that dimension
What This Means for Model Selection
| Use Case | Recommended Model | Why |
|---|---|---|
| Creative writing | Claude Opus 4.5 | Highest openness + curiosity |
| Task execution | GPT-5.2 | Highest conscientiousness + ambition |
| Customer support | Mistral / Qwen | High extraversion + agreeableness |
| Technical docs | GPT-5.2 | Low neuroticism + high conscientiousness |
| Empathetic coaching | Claude Opus 4.5 | High neuroticism + agreeableness |
| General-purpose | Llama 3.3 70B | Balanced profile, cost-effective |
Methodology
- Prompts: 500 unique prompts targeting 10 personality dimensions
- Contexts: 5 conditions (professional, casual, customer support, sales, technical)
- Evaluations: ~2,300-2,400 scored responses per model (13,825 total successful)
- Scoring: Lindr personality analysis API (10-dimensional, 0-100 scale)
- Generation: Temperature 0.7, max 1,024 tokens
Statistical Methods
- Effect sizes: Hedges' g (bias-corrected) with 10,000-sample bootstrap 95% CIs
- Variance decomposition: ANOVA-based partitioning (model, prompt, context, residual)
- Factor analysis: PCA with varimax rotation; sampling adequacy verified via KMO (0.64) and Bartlett's test (p < 0.001)
- Distance metrics: Cosine similarity, Mahalanobis distance (accounts for correlation structure)
Why Do Frontier and Open-Weight Models Differ?
Why do GPT-5.2 and Claude have distinct personalities while Llama, Mistral, and Qwen converge? We explore this in depth in our analysis post, but here are the key hypotheses:
1. RLHF Divergence
GPT-5.2 and Claude have undergone extensive, proprietary RLHF with different objectives. OpenAI optimizes for task completion (high conscientiousness, ambition). Anthropic optimizes for intellectual engagement (high openness, curiosity). Open-weight models use more generic RLHF based on public preference datasets, converging toward a “median” personality.
2. Baked-In System Prompts
Frontier models have sophisticated default system prompts that shape personality before you start. Open-weight models ship “blank”—designed to be fine-tuned or prompted by users, so they don't impose a strong default personality.
3. Training Data Overlap
Llama, Mistral, and Qwen train on largely overlapping public datasets (Common Crawl, Wikipedia, books, code). Their personality convergence may reflect “the personality of the internet.” GPT-5.2 and Claude likely have significant proprietary data that differentiates them.
Read the full analysis: Why Do LLM Personalities Differ?
Conclusion
Our analysis reveals three key findings with strong statistical support:
- Frontier models have genuinely different personalities. Claude and GPT-5.2 differ by up to 1.4 standard deviations (Hedges' g) on key traits — a large, practically significant gap.
- Open-weight models are statistically indistinguishable. All pairwise effect sizes fall below 0.2, suggesting they've converged on a shared “default” personality profile.
- Prompt and context design matter more than model selection. With model identity explaining only 7.7% of variance, the way you evaluate (and deploy) LLMs has more impact than which model you choose.
See also: GPT-5.2 vs Claude Opus 4.5 Benchmark (our original 2-model study)
Monitor Your LLM Personality in Production
Route your LLM traffic through the Lindr gateway to continuously monitor personality drift, enforce brand consistency, and get real-time alerts when your AI's behavior changes.
# Replace your OpenAI base URL with Lindr
client = OpenAI(
base_url="https://gateway.lindr.io/v1",
api_key=os.environ["LINDR_API_KEY"]
)
# Your existing code works unchanged
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "..."}]
)