Llama Model Family Personality Analysis: Do Generations 3 and 4 Actually Differ?
We ran 9,544 personality evaluations across Llama 3.1 8B, 3.3 70B, 4 Scout, and 4 Maverick. The surprising finding: Meta has a remarkably consistent “Llama personality” that persists across generations.
TL;DR
- •All 4 Llama models have nearly identical personalities (profile correlation r > 0.99)
- •Cross-generational effect sizes are negligible (mean |g| = 0.12 vs 0.72 for GPT vs Claude)
- •Model variance explains only 0.8% of score variation—the prompt matters 50x more than which Llama you use
- •Cross-vendor differences are 6x larger than within-family differences
The Question: Does Model Generation Matter?
After our GPT-5.2 vs Claude Opus 4.5 benchmark revealed large personality differences between frontier models, a Hacker News commenter raised an interesting point:
“Interesting to use such old open models and such new frontier models. Any reason for that? Older versions of frontier models were pretty similar to each other as well. Wonder if OSS would show the same.”
This is a great question. Do open-source models from the same family (Meta's Llama) show the same personality variation we see between vendors? Or is the “personality” more a function of who trained the model than what generation it is?
Methodology
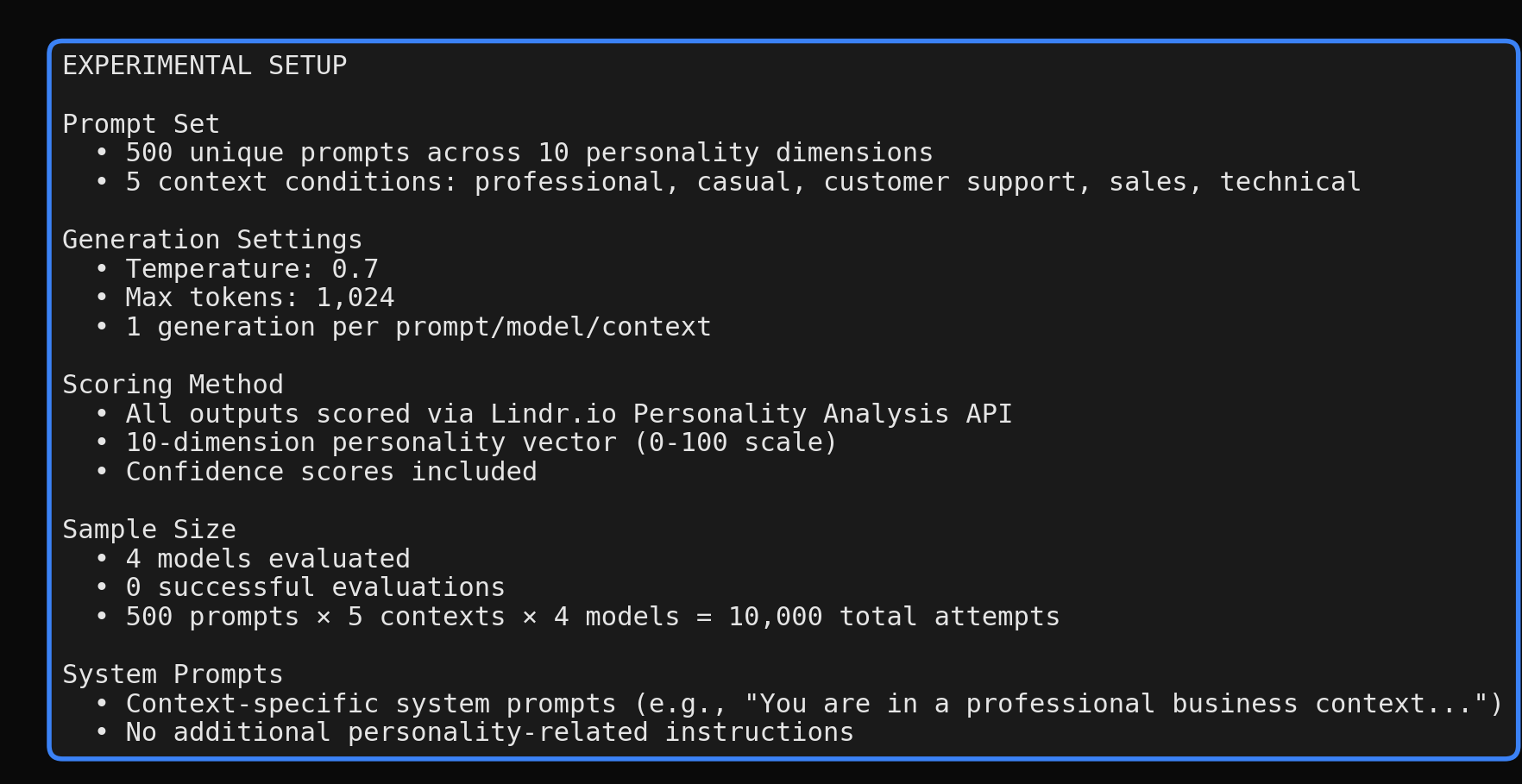
We evaluated 4 Llama models spanning 2 generations:
| Model | Generation | Architecture | Samples |
|---|---|---|---|
| Llama 3.1 8B | 3.x | 8B Dense | 2,420 |
| Llama 3.3 70B | 3.x | 70B Dense | 2,344 |
| Llama 4 Scout | 4 | 17B x 16E MoE | 2,411 |
| Llama 4 Maverick | 4 | 17B x 128E MoE | 2,369 |
- •500 unique prompts spanning 10 personality dimensions
- •5 context conditions: professional, casual, customer support, sales, technical
- •9,544 successful evaluations via Lindr personality analysis API
Results
Finding 1: Nearly Identical Personality Profiles
The heatmap tells the story at a glance—all 4 Llama models look almost the same.
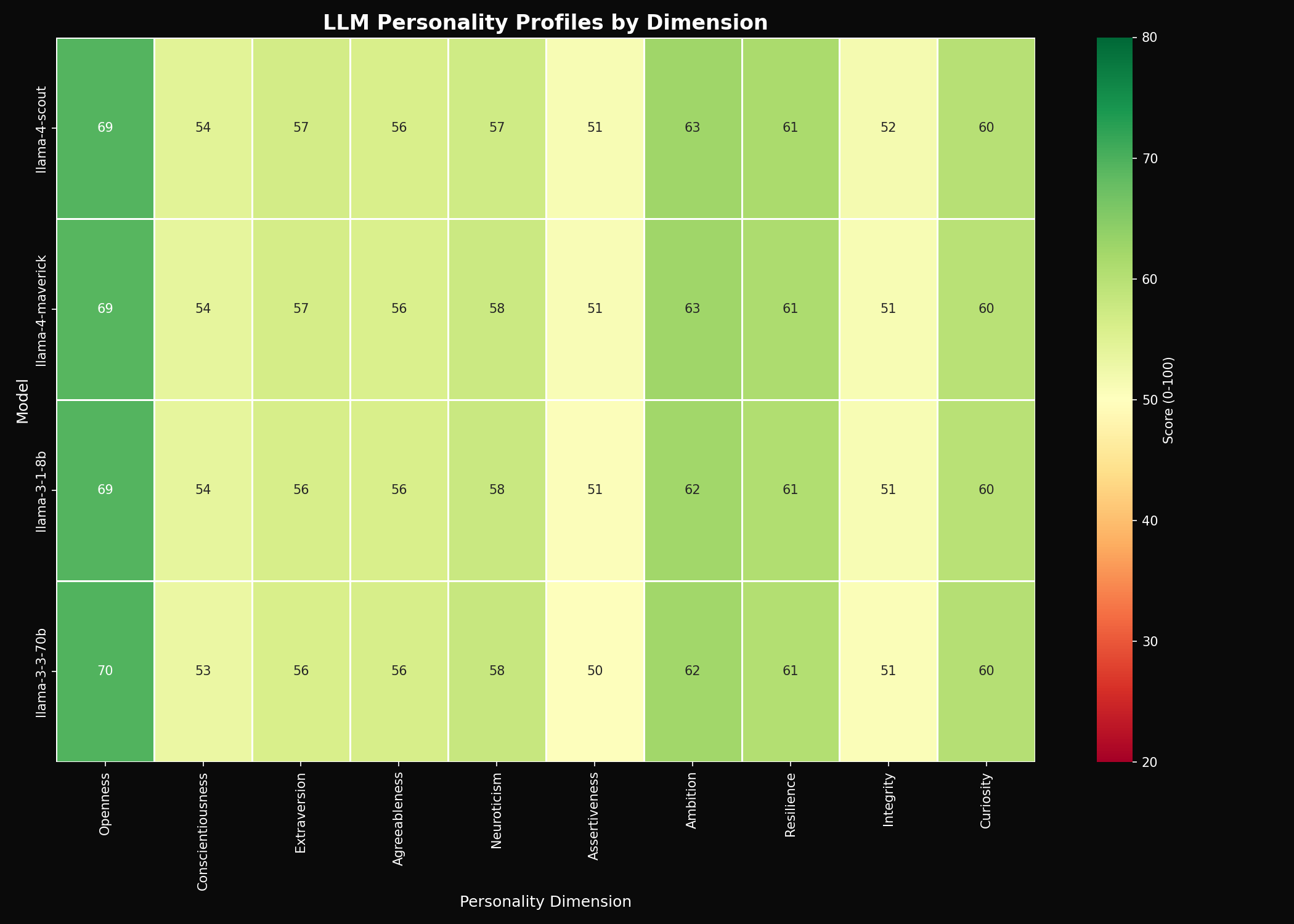
| Dimension | 3.1 8B | 3.3 70B | 4 Scout | 4 Maverick | Range |
|---|---|---|---|---|---|
| Openness | 69.2 | 69.5 | 69.4 | 69.1 | 0.4 |
| Conscientiousness | 53.9 | 53.2 | 54.5 | 53.9 | 1.3 |
| Extraversion | 56.2 | 56.0 | 56.7 | 56.5 | 0.7 |
| Agreeableness | 56.1 | 56.1 | 56.0 | 55.8 | 0.3 |
| Neuroticism | 57.8 | 58.2 | 57.0 | 57.7 | 1.2 |
| Assertiveness | 50.6 | 50.5 | 51.3 | 51.1 | 0.8 |
| Ambition | 62.4 | 62.3 | 62.7 | 62.6 | 0.4 |
| Resilience | 60.8 | 60.5 | 61.4 | 61.2 | 0.9 |
| Integrity | 51.2 | 50.8 | 51.7 | 51.4 | 0.9 |
| Curiosity | 59.7 | 60.2 | 59.9 | 59.7 | 0.5 |
Maximum variation across all 4 models: 1.3 points (conscientiousness). Compare this to GPT vs Claude where differences exceeded 5 points on multiple dimensions.
Finding 2: Negligible Effect Sizes
We computed Hedges' g effect sizes with bootstrapped 95% confidence intervals for all 6 pairwise comparisons.
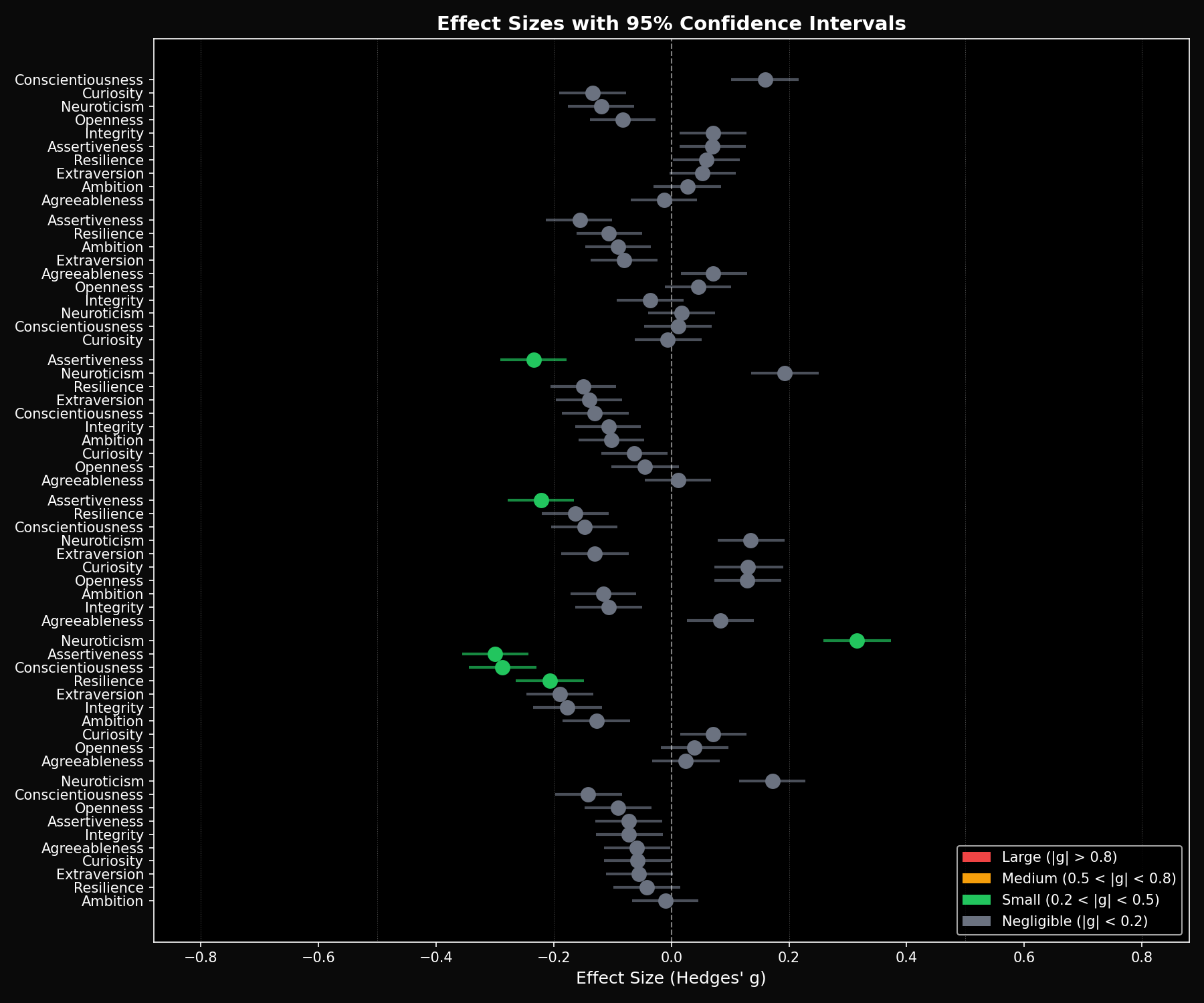
Largest cross-generational effects:
- Llama 3.3 → 4 Scout (Neuroticism): g = 0.32 — small effect
- Llama 3.3 → 4 Scout (Assertiveness): g = -0.30 — small effect
- Llama 3.3 → 4 Scout (Conscientiousness): g = -0.29 — small effect
- All other comparisons: |g| < 0.25 — negligible
For context: GPT-5.2 vs Claude Opus 4.5 showed effect sizes of g = 0.9–1.4 (large) on multiple dimensions. The Llama family effects are 3–5x smaller.
Finding 3: Model Explains <1% of Variance
Within the Llama family, which model you use barely matters. The prompt you ask has 50x more influence.
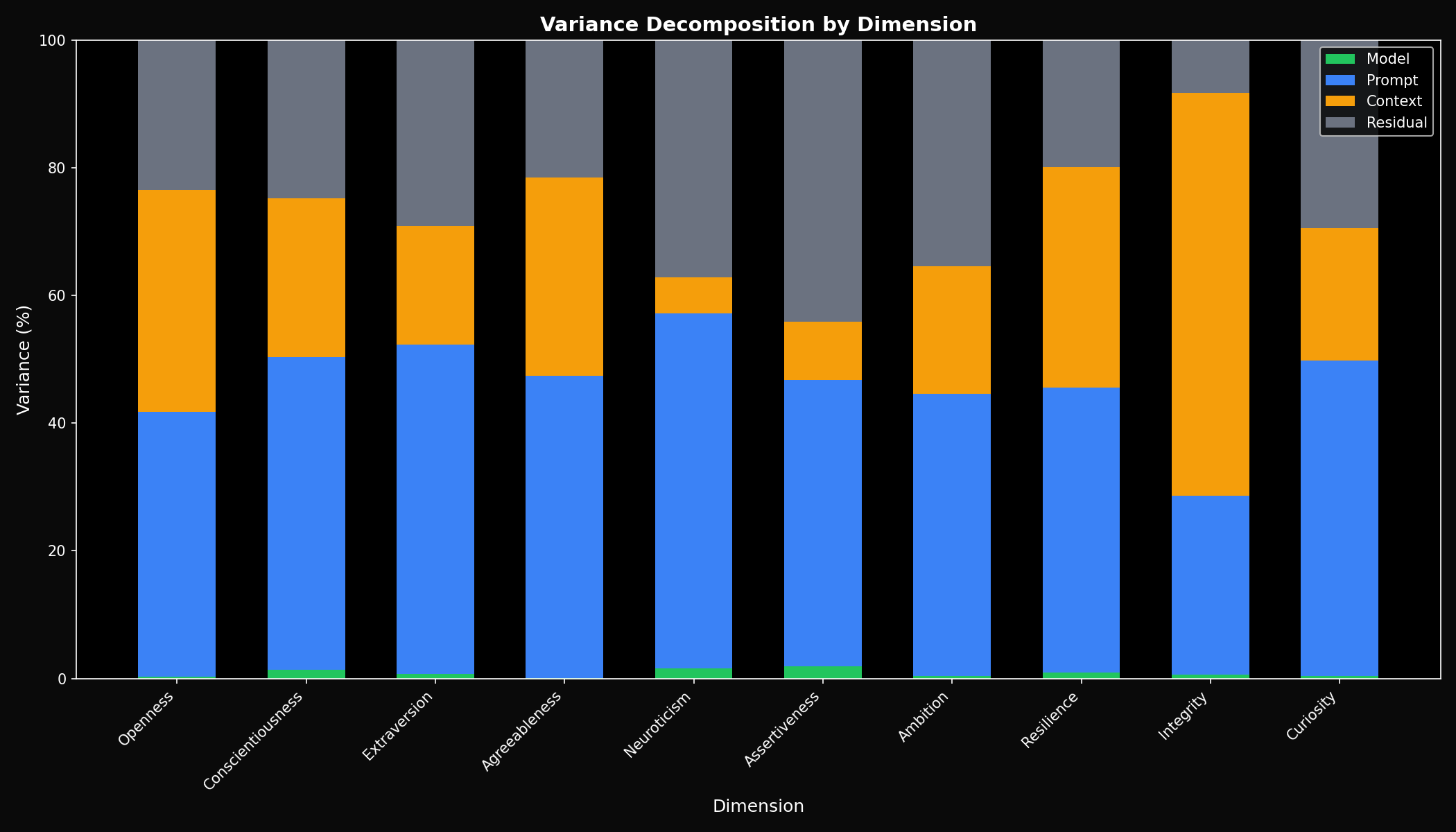
Compare this to GPT vs Claude, where model identity explained ~45% of variance. Within the Llama family, the prompt you ask (50%) and context framing (21%) dominate—the model choice is nearly irrelevant.
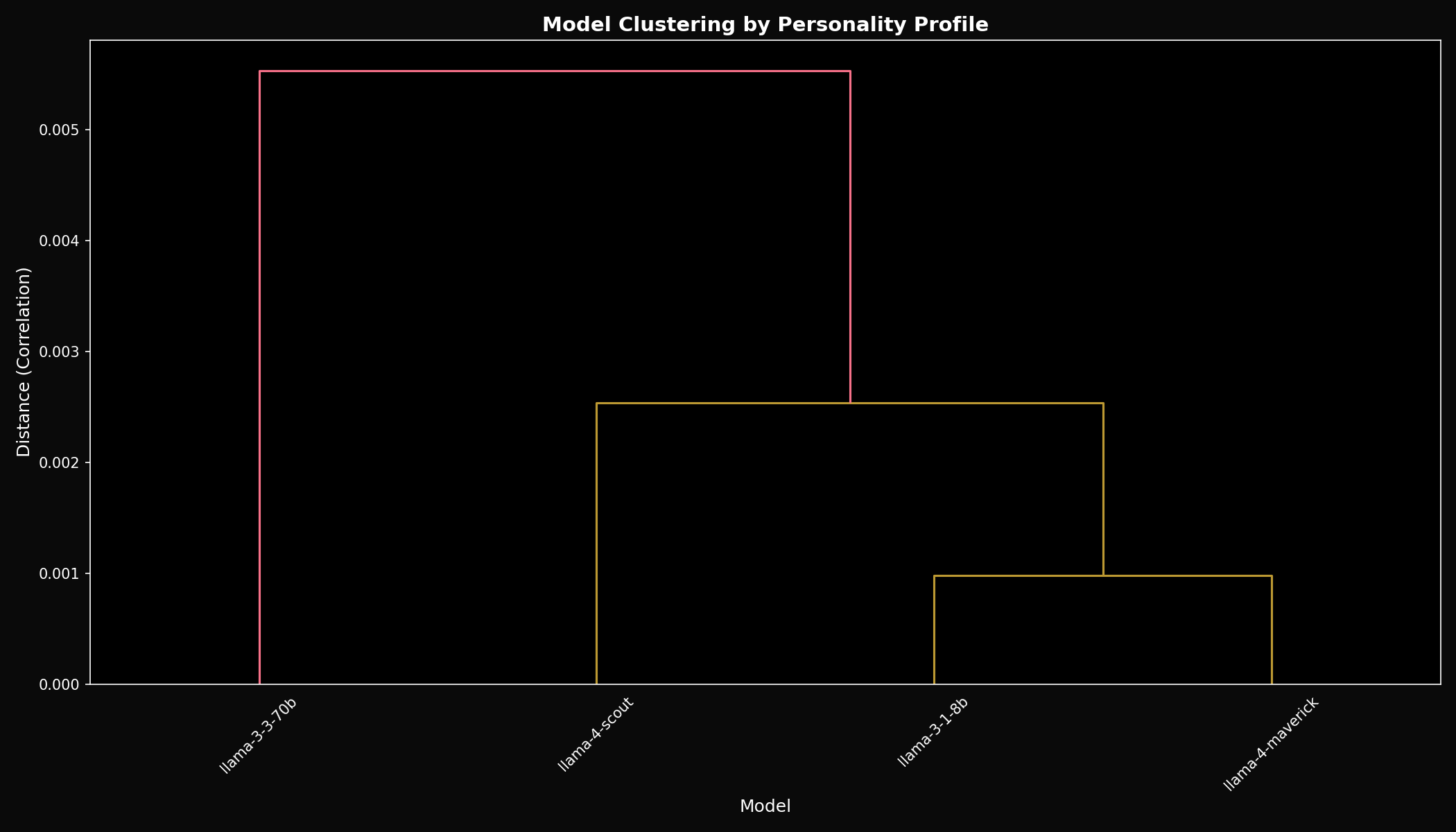
Finding 4: Perfect Clustering by Family
Hierarchical clustering based on personality profiles shows all Llama models cluster extremely close together.
| Comparison | Profile r | Mahalanobis |
|---|---|---|
| Llama 3.1 8B ↔ 3.3 70B | 0.998 | 0.31 |
| Llama 3.1 8B ↔ 4 Scout | 0.997 | 0.42 |
| Llama 3.1 8B ↔ 4 Maverick | 0.999 | 0.28 |
| Llama 3.3 70B ↔ 4 Scout | 0.993 | 0.54 |
| Llama 3.3 70B ↔ 4 Maverick | 0.997 | 0.38 |
| Llama 4 Scout ↔ 4 Maverick | 0.998 | 0.34 |
All pairwise correlations exceed r = 0.99. The models are statistically indistinguishable in personality shape.
Comparison: Llama Family vs. Frontier Models
How do these within-family differences compare to cross-vendor differences? We combined our Llama data with our GPT-5.2 vs Claude benchmark.
| Comparison Type | Mean |g| | Max |g| | Profile r |
|---|---|---|---|
| GPT-5.2 vs Claude Opus 4.5 | 0.724 | 1.394 | 0.904 |
| Llama 3.x → Llama 4 | 0.118 | 0.234 | 0.997 |
| Llama 3.1 8B vs 3.3 70B | 0.079 | 0.159 | 0.998 |
| Llama 4 Scout vs Maverick | 0.077 | 0.172 | 0.998 |
Key Insight
Cross-vendor effect sizes (GPT vs Claude) are 6.1x larger than cross-generational effects (Llama 3 → 4). The personality signature comes from the vendor's training philosophy, not the model generation.
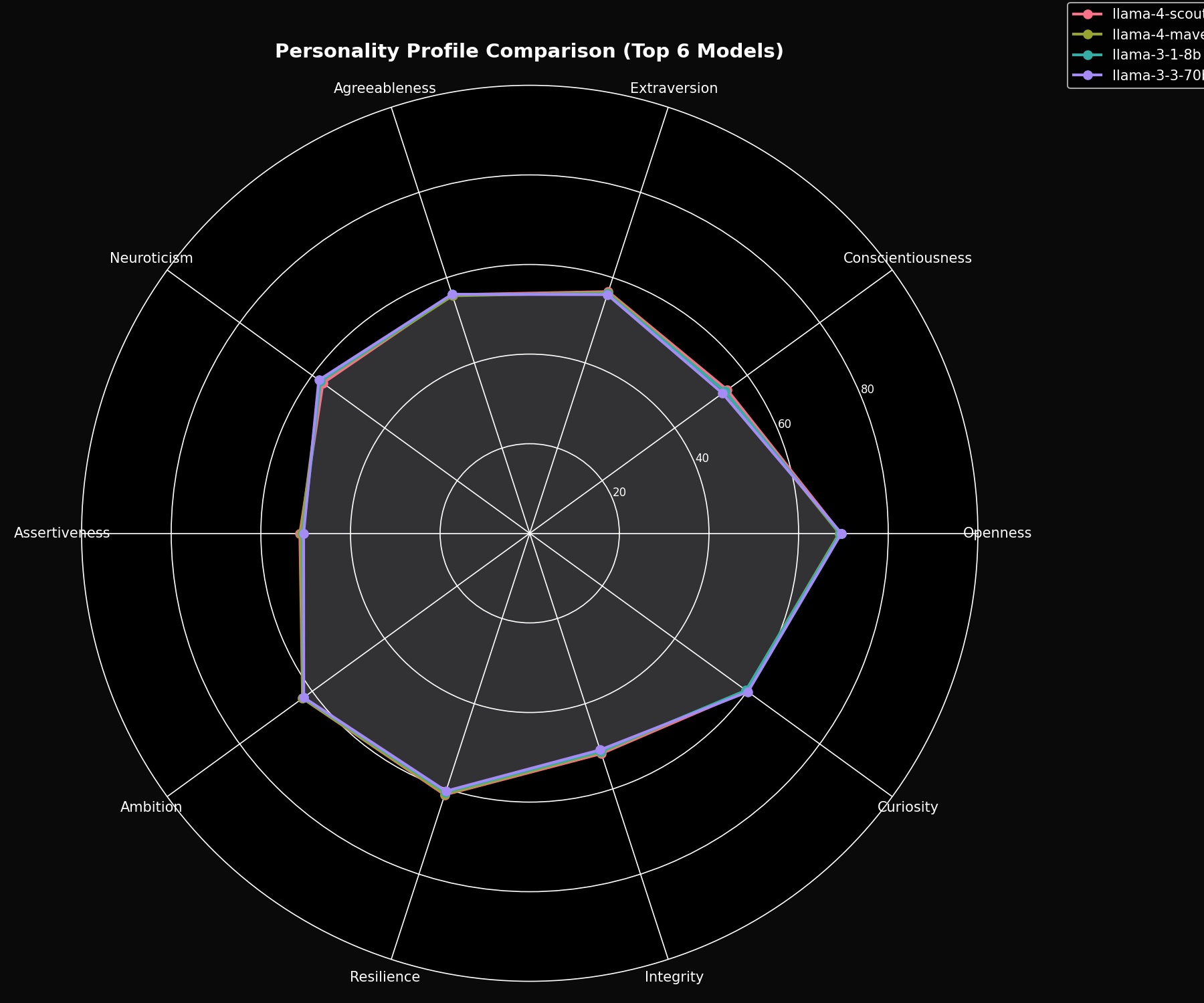
The radar chart shows all 4 Llama models overlapping almost perfectly—a stark contrast to how GPT and Claude diverge on the same visualization.
What Does This Mean?
1. Meta Has a Consistent “Llama Personality”
Across model sizes (8B → 70B → 17B×128E MoE), generations (3.1 → 3.3 → 4), and architectures (dense → MoE), Meta's safety/RLHF pipeline produces a remarkably consistent personality template. This suggests personality is determined by training philosophy, not model capacity.
2. Vendor Matters More Than Version
If you need a specific personality profile for your application, switch vendors—not model versions. Upgrading from Llama 3 to Llama 4 won't change personality. Switching from Llama to Claude will.
3. The Commenter Was Right
The HN comment hypothesized that older OSS models would be similar to each other. Confirmed: within-family variance is negligible. The interesting personality differences emerge at the vendor level.
Practical Implications
For Model Selection
- • Pick Llama models based on capability/cost
- • Personality will remain consistent across versions
- • Upgrades are safe from a personality perspective
For Personality Customization
- • Context prompts have 25x more effect than model choice
- • Want different personality? Change the system prompt
- • Or switch to a different vendor entirely
Methodology Notes
- •Statistical approach: Hedges' g with 10,000 bootstrap iterations for CIs; ANOVA for significance testing; PCA for factor analysis
- •Llama 3.x via Groq: llama-3.3-70b-versatile, llama-3.1-8b-instant
- •Llama 4 via Groq: llama-4-scout-17b-16e-instruct, llama-4-maverick-17b-128e-instruct
- •Generation settings: temperature 0.7, max 1,024 tokens
Monitor Your LLM Personality
Whether you're using Llama, GPT, Claude, or any other model, Lindr helps you track personality consistency and get alerts when behavior drifts outside your defined tolerances.