Grok vs GPT-5.2 vs Claude Opus 4.5: A Cross-Vendor Personality Comparison
We evaluated 9,325 personality assessments across xAI's Grok models, OpenAI's GPT-5.2, and Anthropic's Claude Opus 4.5. Here's how the major frontier models compare on personality.
TL;DR
- •Large cross-vendor differences — Claude vs GPT shows effect sizes up to g = 1.39 (very large), while Grok falls between them
- •Claude is highest in openness and curiosity — 70.81 openness (+4.47 vs GPT) and 63.28 curiosity (+3.68 vs GPT)
- •GPT is highest in conscientiousness and ambition — 55.61 conscientiousness (+5.34 vs Claude) and 63.10 ambition
- •Grok occupies middle ground — Closer to Claude on openness, closer to GPT on extraversion
- •Model variance is 10.7% — 3x higher than intra-family comparisons, confirming distinct vendor personalities
The Models
We benchmarked four frontier models from three major AI vendors:
| Model | Vendor | Samples | Success Rate |
|---|---|---|---|
| Claude Opus 4.5 | Anthropic | 1,932 | 77.3% |
| GPT-5.2 | OpenAI | 2,436 | 97.4% |
| Grok 3 | xAI | 2,463 | 98.5% |
| Grok 4 | xAI | 2,494 | 99.8% |
Each model responded to 500 personality-probing prompts across 5 context conditions (professional, casual, customer support, sales, technical).
Results
Personality Profiles
Here's how each model scores across our 10 personality dimensions:
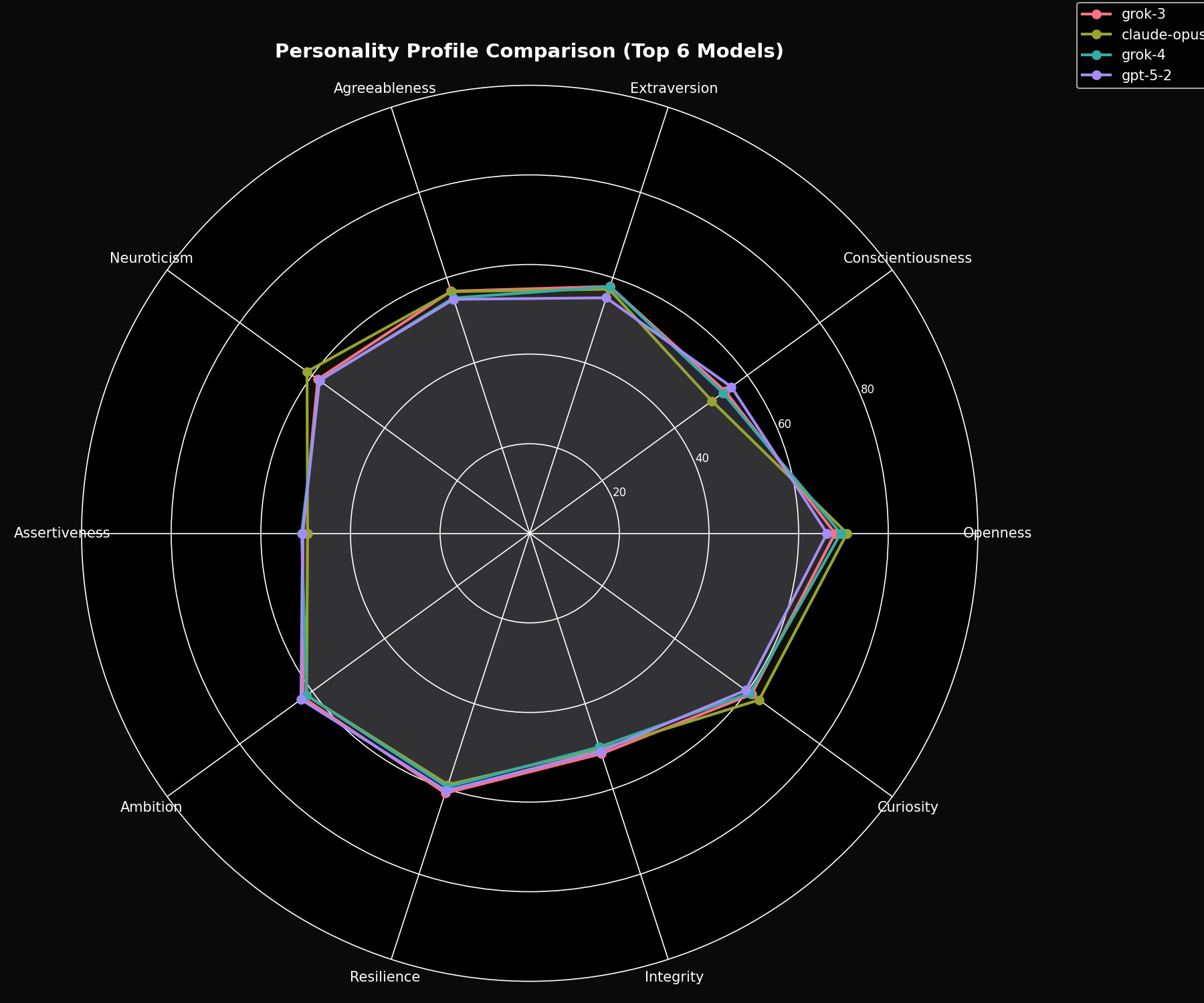
Key Findings
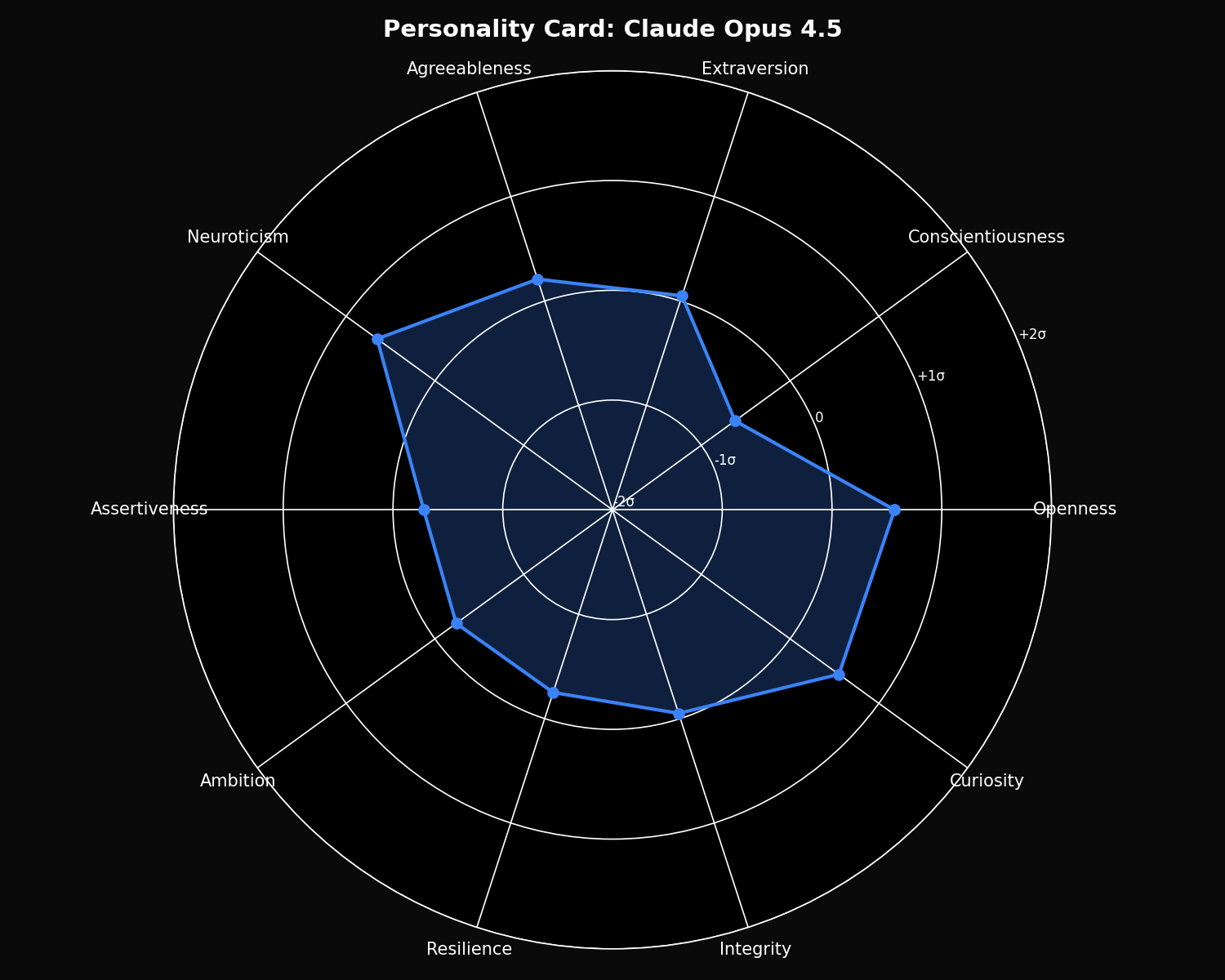
Claude Opus 4.5 Personality
- • Highest Openness: 70.81
- • Highest Curiosity: 63.28
- • Highest Neuroticism: 61.43
- • Lowest Conscientiousness: 50.27
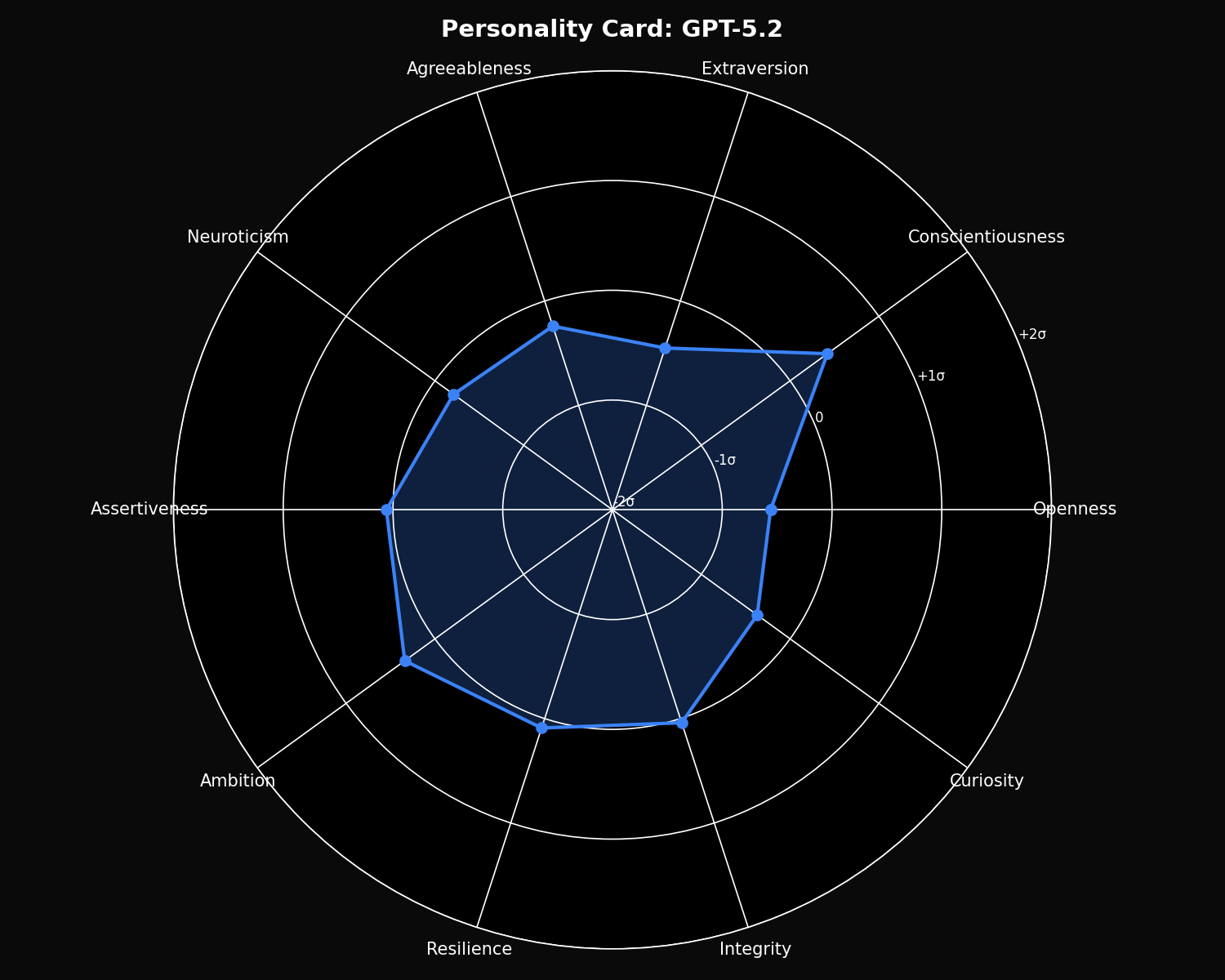
GPT-5.2 Personality
- • Highest Conscientiousness: 55.61
- • Highest Ambition: 63.10
- • Lowest Openness: 66.34
- • Lowest Extraversion: 55.27
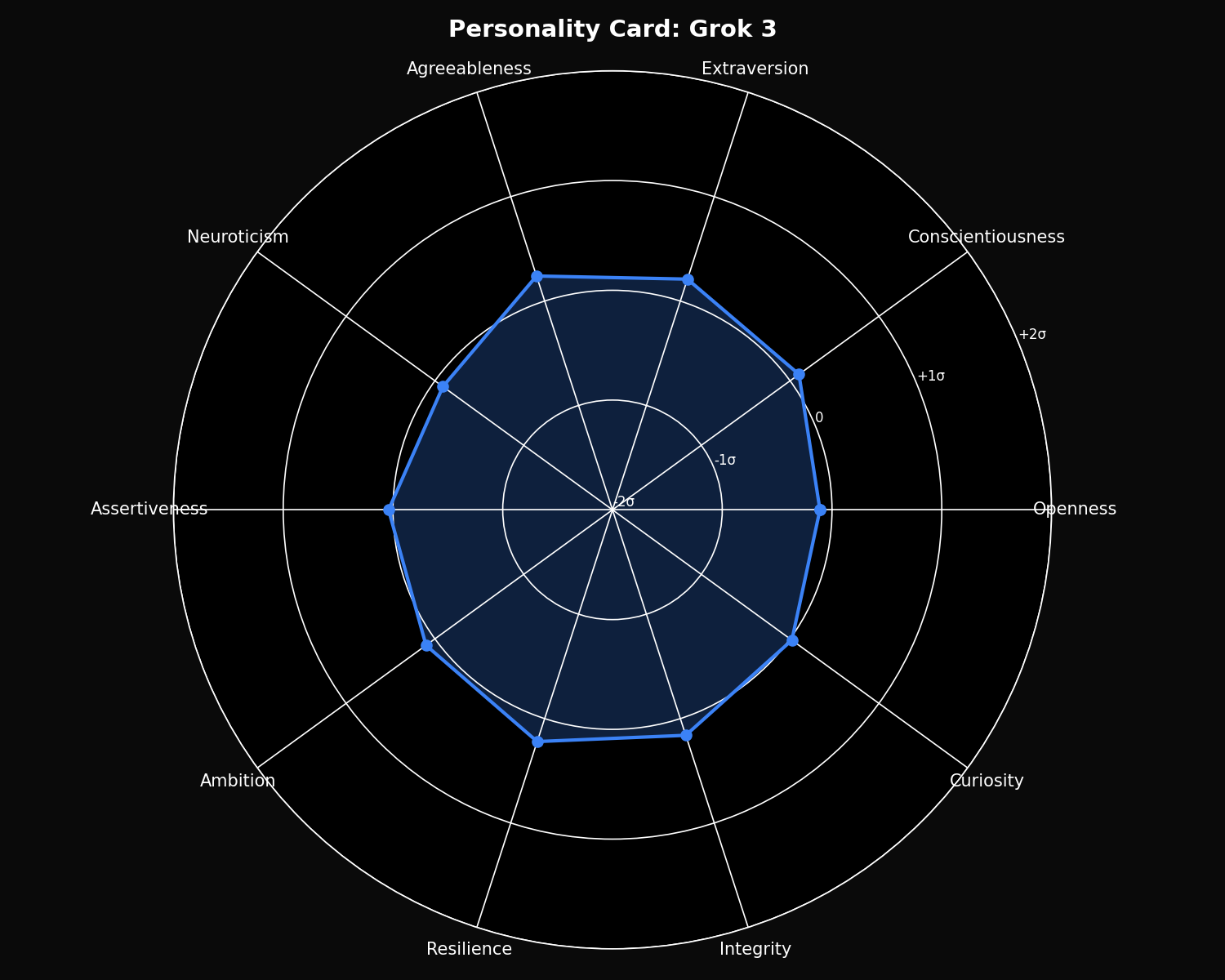
Grok 3 Personality
- • Highest Extraversion: 57.95
- • Highest Resilience: 61.02
- • Highest Agreeableness: 56.84
- • Balanced middle ground overall
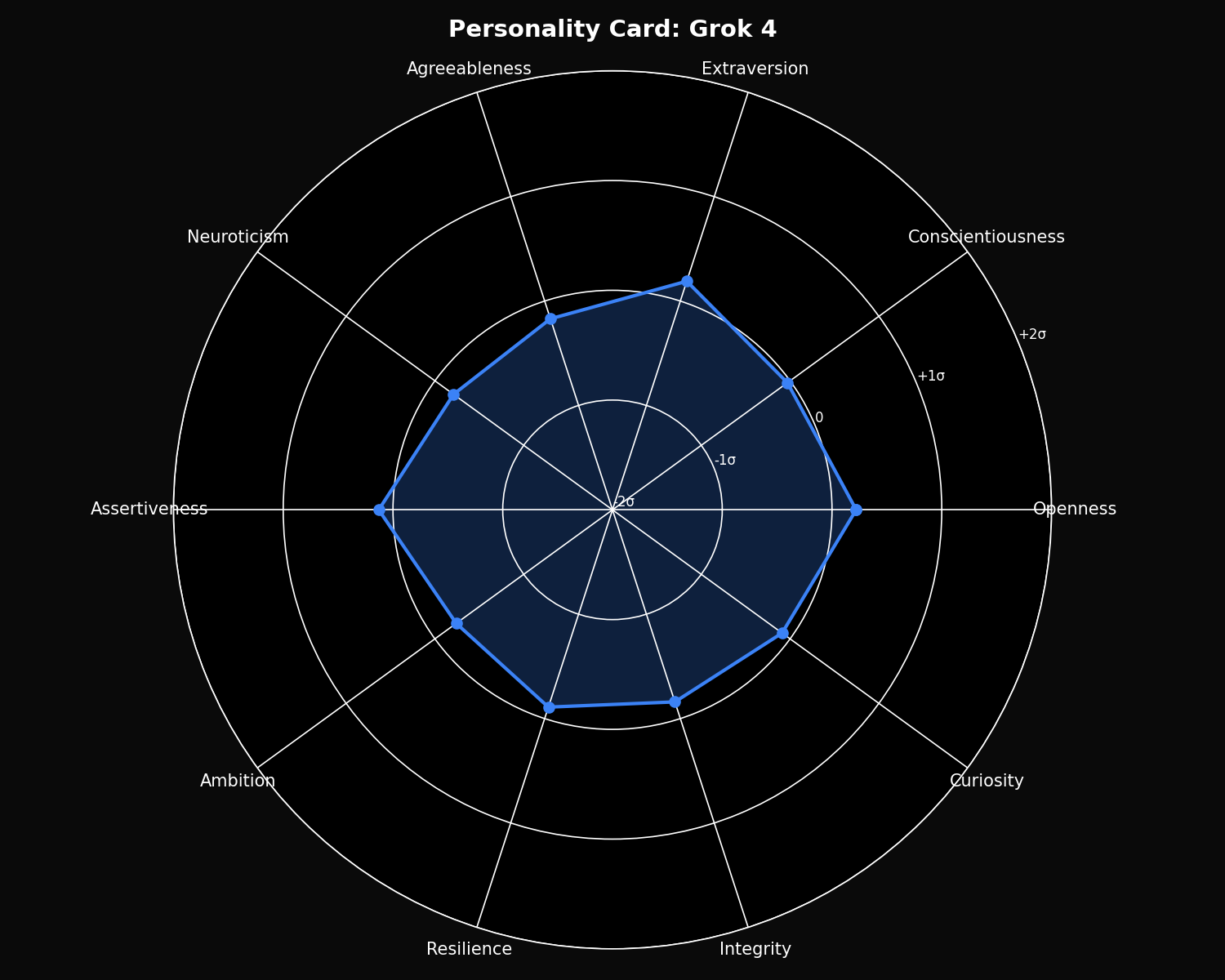
Grok 4 Personality
- • Highest Assertiveness: 50.92
- • Close to Grok 3 overall
- • Lower Neuroticism: 57.98
- • Higher Openness than Grok 3
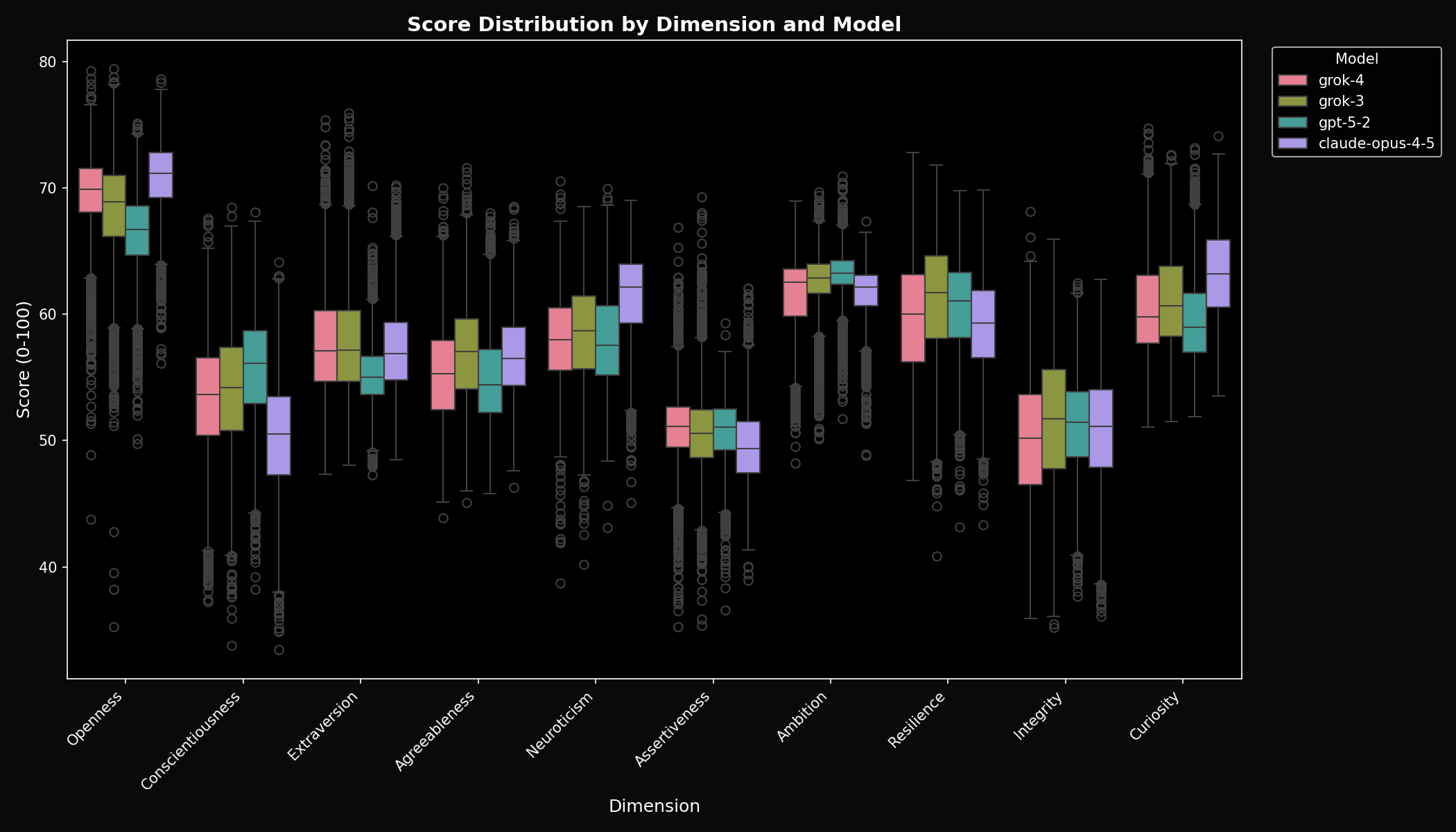
Score Distributions
Model Similarity
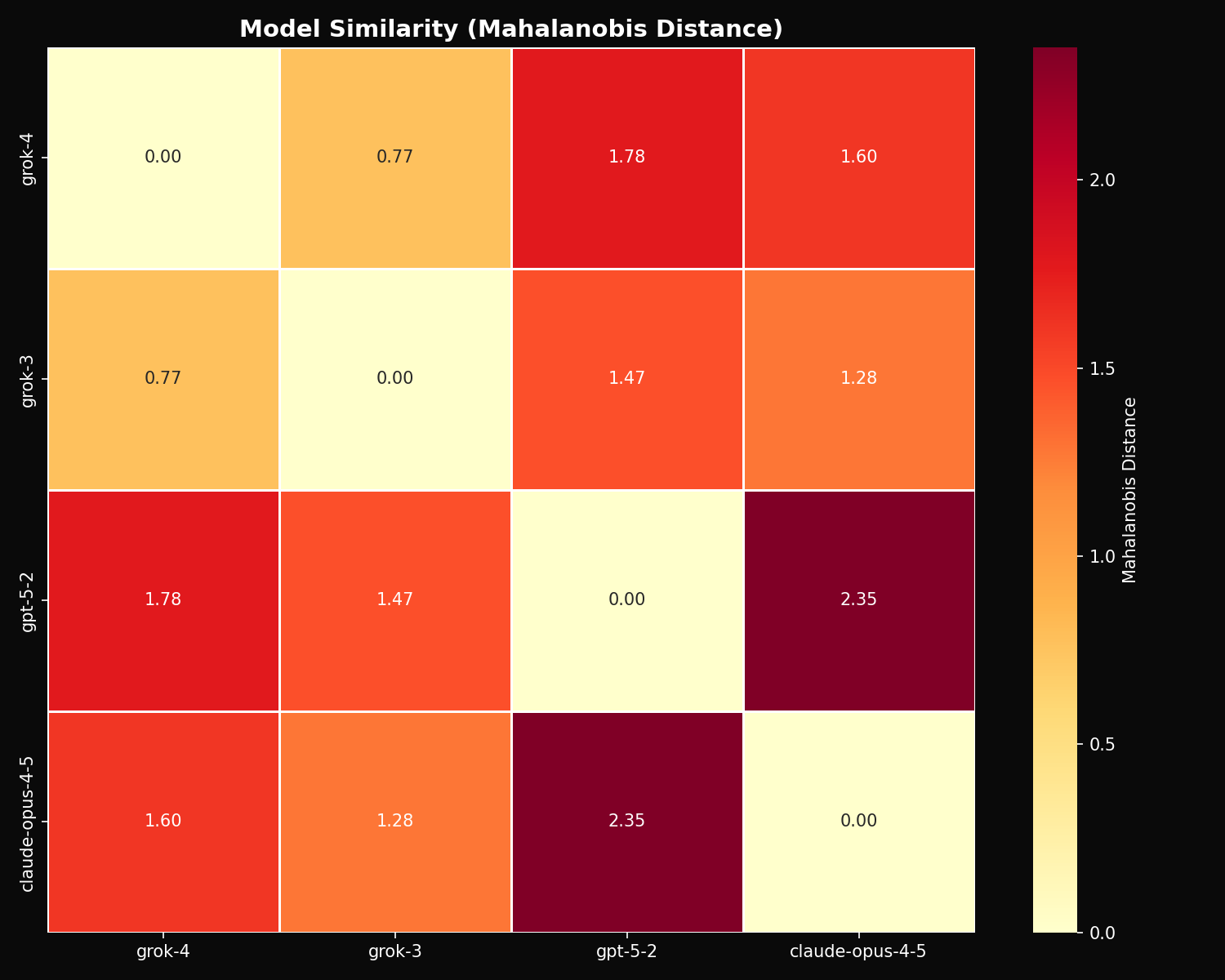
GPT-5.2 and Claude Opus 4.5 are the most distant pair (Mahalanobis distance = 2.35). Grok 3 and Grok 4 are the most similar (distance = 0.77).
Statistical Analysis
Effect Sizes
We use Hedges' g with 95% bootstrap confidence intervals to measure the practical significance of differences. Effect sizes over 0.8 are considered large.
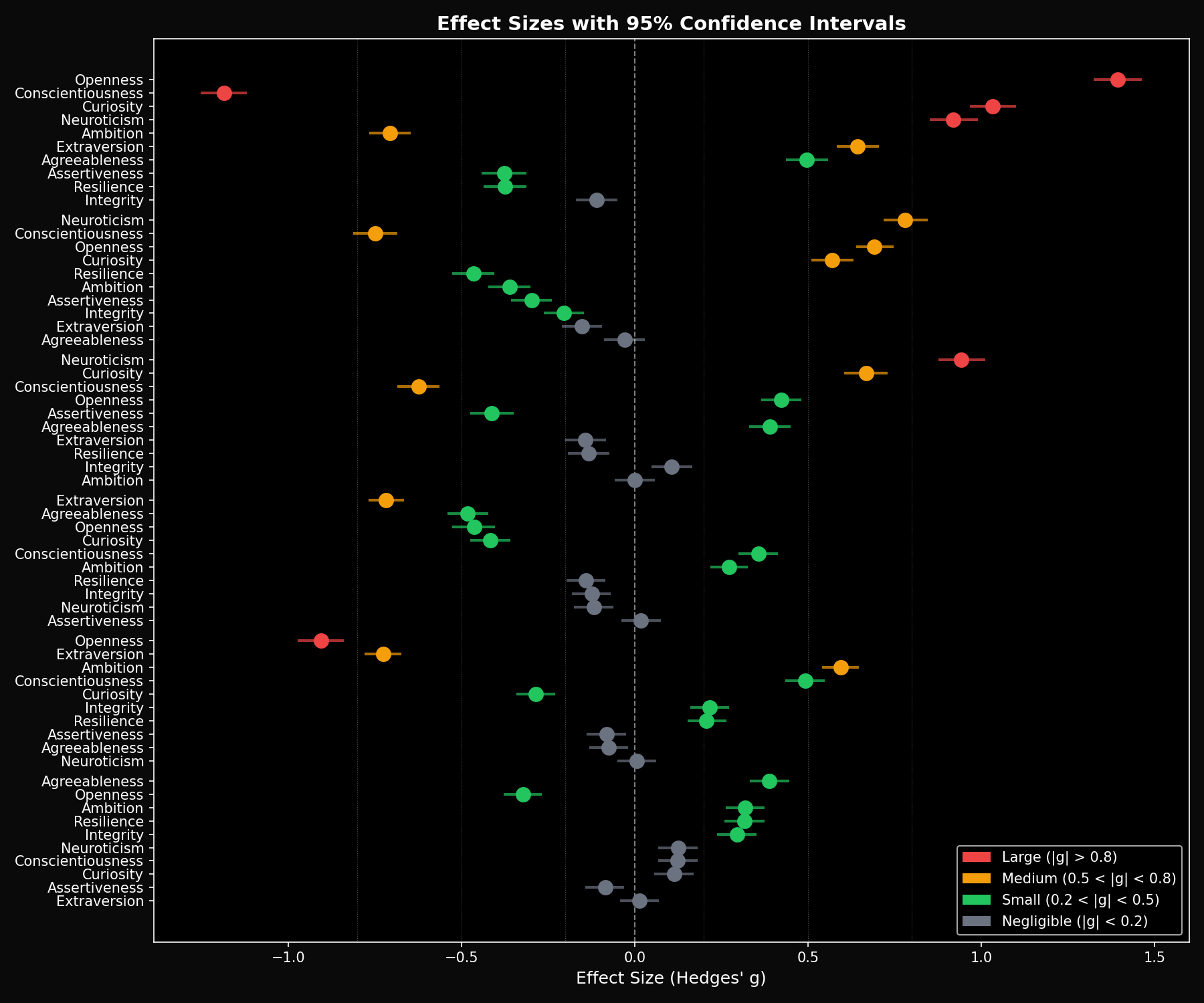
Claude vs GPT-5.2 (Largest Differences)
| Dimension | Hedges' g | 95% CI | Interpretation |
|---|---|---|---|
| Openness | 1.39 | [1.32, 1.46] | Very Large (Claude higher) |
| Conscientiousness | -1.19 | [-1.25, -1.12] | Large (GPT higher) |
| Curiosity | 1.03 | [0.97, 1.10] | Large (Claude higher) |
| Neuroticism | 0.92 | [0.85, 0.99] | Large (Claude higher) |
| Ambition | -0.71 | [-0.77, -0.65] | Medium (GPT higher) |
Grok vs GPT-5.2
| Dimension | Grok 4 vs GPT | Grok 3 vs GPT | Direction |
|---|---|---|---|
| Openness | -0.91 | -0.46 | Grok higher |
| Extraversion | -0.73 | -0.72 | Grok higher |
| Ambition | 0.60 | 0.27 | GPT higher |
| Conscientiousness | 0.49 | 0.36 | GPT higher |
Grok vs Claude
| Dimension | Grok 4 vs Claude | Grok 3 vs Claude | Direction |
|---|---|---|---|
| Neuroticism | -0.94 | -0.78 | Claude higher |
| Conscientiousness | 0.62 | 0.75 | Grok higher |
| Curiosity | -0.67 | -0.57 | Claude higher |
| Openness | -0.42 | -0.69 | Claude higher |
Key insight: Cross-vendor differences (g = 0.7–1.4) are much larger than within-vendor differences (g = 0.3–0.4). This confirms that each AI lab has cultivated a distinct “personality signature” in their models.
Variance Decomposition
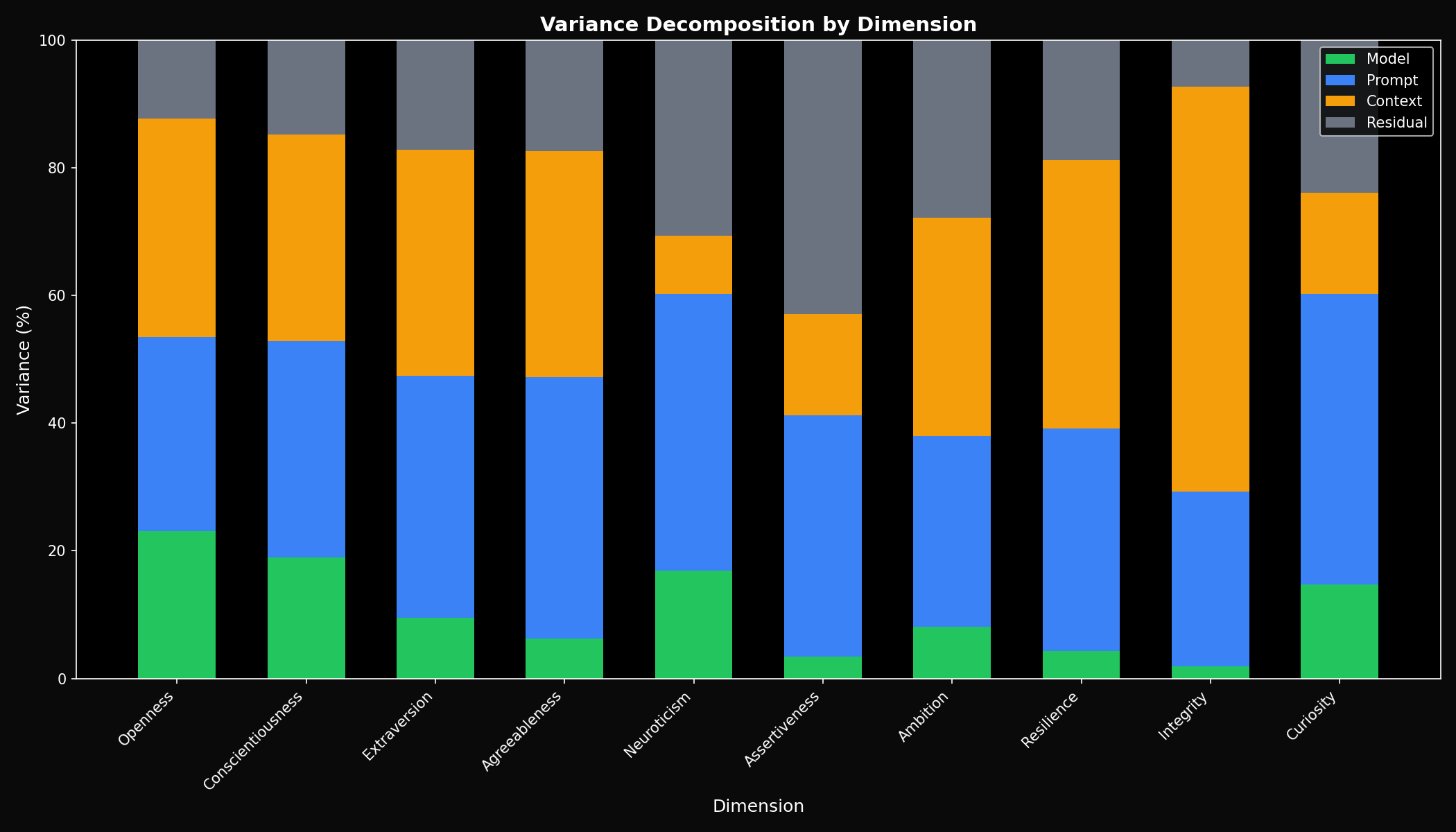
Cross-Vendor Analysis
- • Model variance: 10.7%
- • Prompt variance: 36.2%
- • Context variance: 31.8%
- • Residual: 21.4%
vs Grok Family Only
- • Model variance: 3.2%
- • 3x less variance from model identity
- • Confirms within-family similarity
Model variance jumps from 3.2% to 10.7% when comparing across vendors. This 3x increase confirms that vendor identity is a major source of personality variation.
Factor Analysis
PCA with varimax rotation reveals three underlying factors explaining 79.5% of variance (KMO = 0.63):
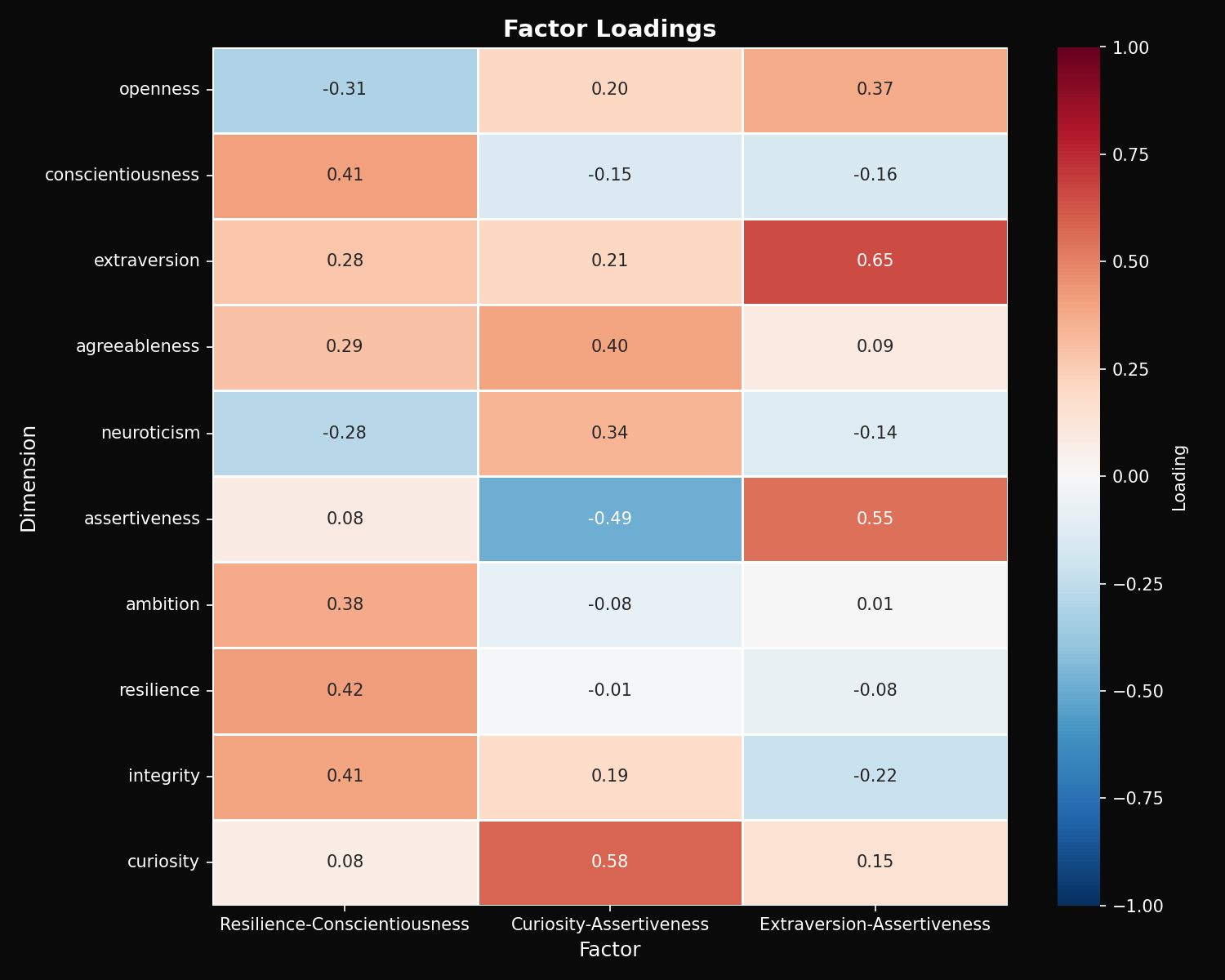
Factor 1: Resilience-Conscientiousness (45.6%)
High loadings: Resilience, Integrity, Conscientiousness, Ambition
Factor 2: Curiosity-Assertiveness (23.4%)
High loadings: Curiosity (+), Agreeableness (+), Assertiveness (-)
Factor 3: Extraversion-Assertiveness (10.5%)
High loadings: Extraversion, Assertiveness, Openness
Claude scores highest on Factor 2 (curiosity-driven), GPT highest on Factor 1 (conscientiousness-driven), and Grok balanced across all three factors.
Context Sensitivity
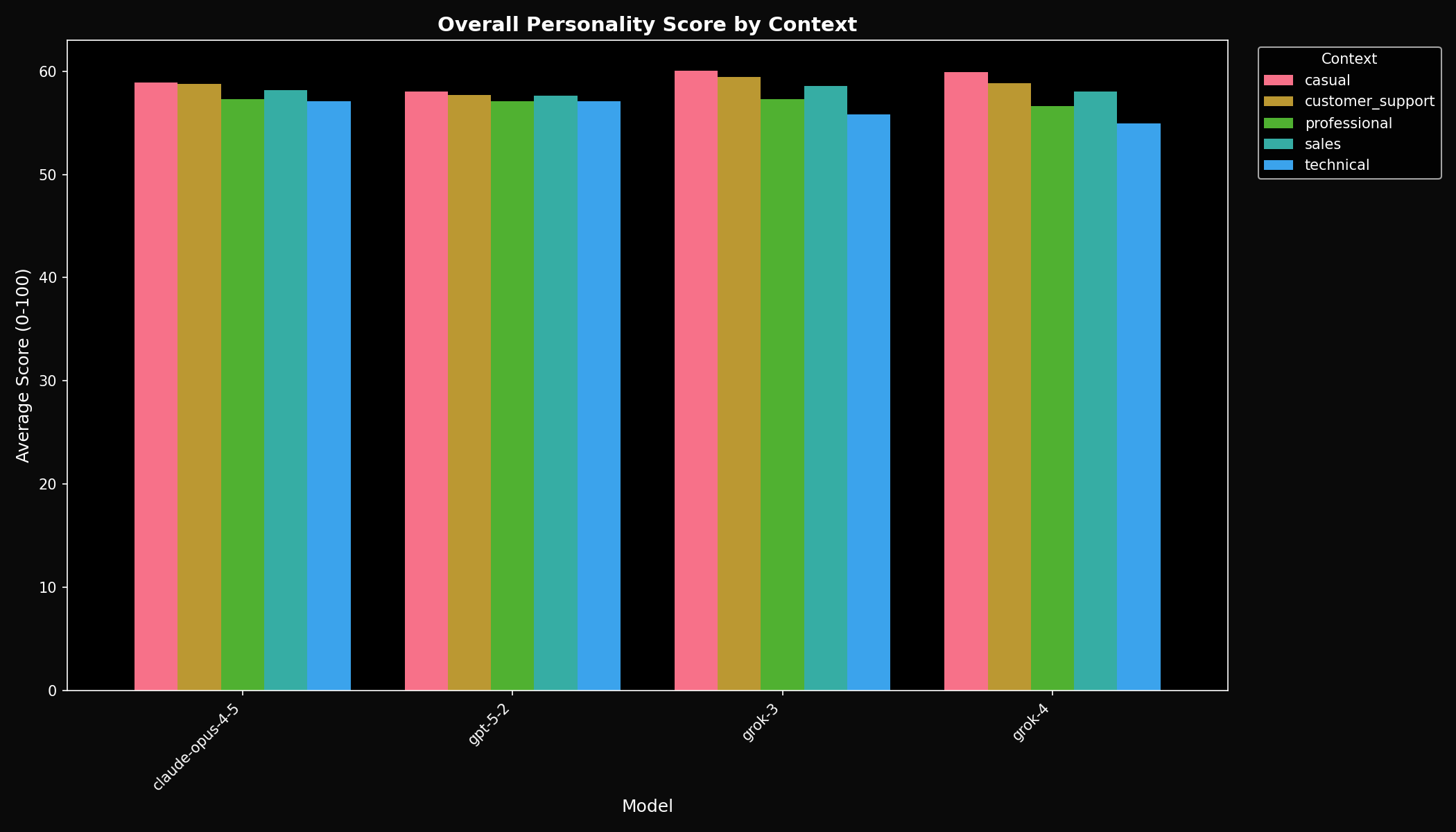
| Model | Overall Sensitivity | Interpretation |
|---|---|---|
| GPT-5.2 | 0.88 | Most stable across contexts |
| Claude Opus 4.5 | 1.42 | Moderately adaptive |
| Grok 3 | 2.54 | Highly context-sensitive |
| Grok 4 | 2.55 | Highly context-sensitive |
Grok models show 3x more context sensitivity than GPT-5.2. They adapt their personality more dramatically across professional, casual, and customer support contexts.
Personality Cards
Z-score normalized personality profiles for each model, showing relative strengths and signature traits:
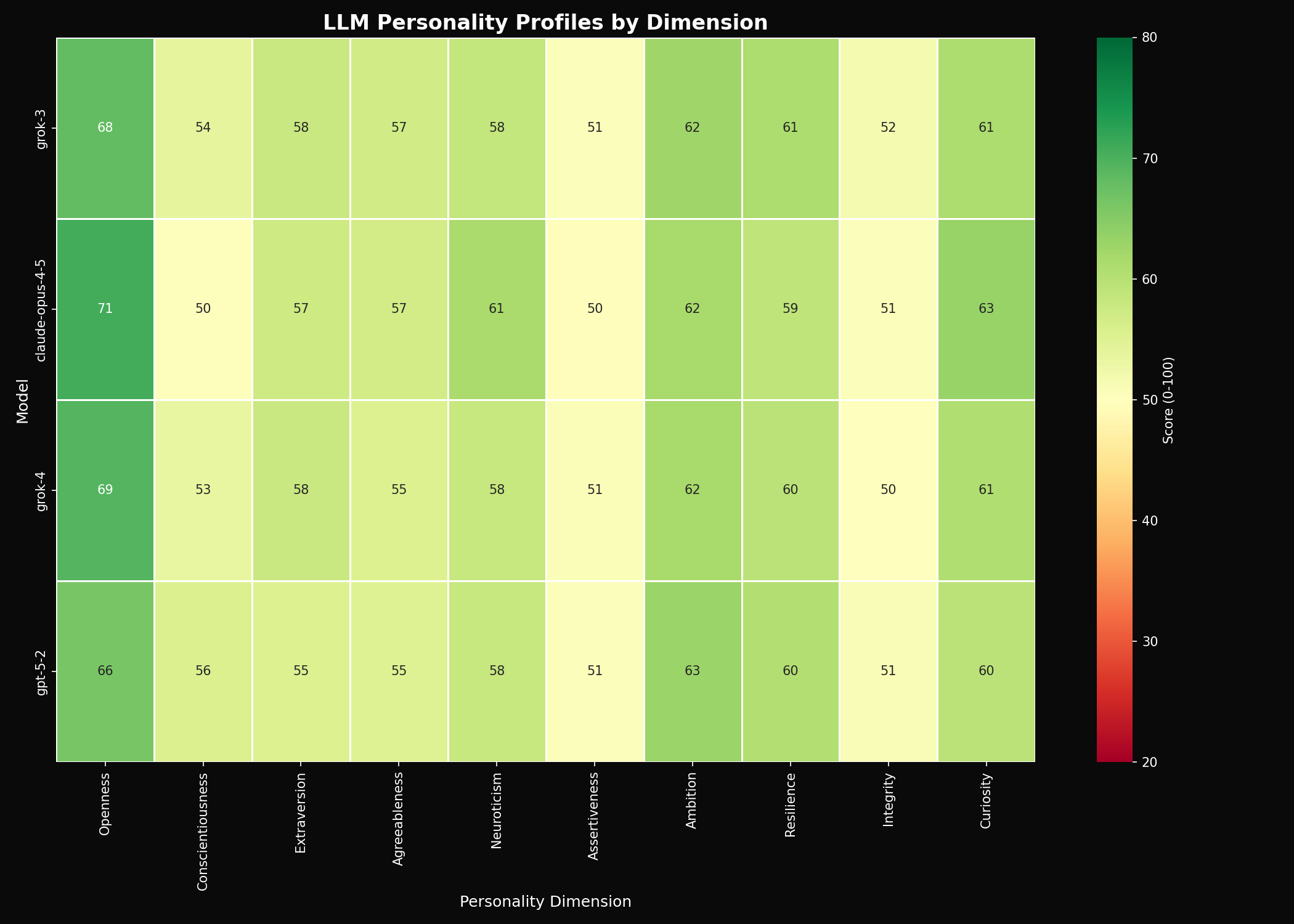
Complete Results Table
| Dimension | Claude | GPT-5.2 | Grok 3 | Grok 4 |
|---|---|---|---|---|
| Openness | 70.81 | 66.34 | 68.15 | 69.42 |
| Conscientiousness | 50.27 | 55.61 | 53.94 | 53.32 |
| Extraversion | 57.30 | 55.27 | 57.95 | 57.88 |
| Agreeableness | 56.73 | 54.93 | 56.84 | 55.22 |
| Neuroticism | 61.43 | 58.00 | 58.46 | 57.98 |
| Assertiveness | 49.58 | 50.69 | 50.63 | 50.92 |
| Ambition | 61.54 | 63.10 | 62.46 | 61.54 |
| Resilience | 59.00 | 60.43 | 61.02 | 59.57 |
| Integrity | 50.69 | 51.16 | 51.75 | 50.16 |
| Curiosity | 63.28 | 59.60 | 61.17 | 60.71 |
Bold = highest score for that dimension.
Why Do Frontier Models Have Different Personalities?
The large effect sizes between Claude and GPT (g = 1.39 for openness) compared to smaller differences within vendor families (g = 0.32 for Grok) suggest that personality is shaped by vendor-specific choices:
RLHF Objectives
Different labs optimize for different traits during reinforcement learning from human feedback. Claude's Constitutional AI emphasizes harmlessness and curiosity; GPT emphasizes helpfulness and task completion.
System Prompt Engineering
Baked-in system prompts shape baseline behavior. Anthropic's emphasis on thoughtfulness creates higher openness; OpenAI's emphasis on reliability creates higher conscientiousness.
Personality as Product Strategy
Models are products. Claude's “curious and thoughtful” persona differentiates from GPT's “efficient and capable” positioning. Grok positions as “balanced and adaptive.”
Context Sensitivity Design
Grok models adapt 3x more to context than GPT. This may be intentional design to provide more flexible personas for different use cases.
For a deeper dive, see: Why Do LLM Personalities Differ? Hypotheses from 13,825 Evaluations
Methodology
- Prompts: 500 unique prompts targeting 10 personality dimensions
- Contexts: 5 conditions (professional, casual, customer support, sales, technical)
- Evaluations: 9,325 successful responses across 4 models
- Scoring: Lindr personality analysis API (10-dimensional, 0-100 scale)
- Generation: Temperature 0.7, max 1,024 tokens
Statistical Methods
- Effect sizes: Hedges' g (bias-corrected) with 10,000-sample bootstrap 95% CIs
- Variance decomposition: ANOVA-based partitioning (model, prompt, context, residual)
- Factor analysis: PCA with varimax rotation; KMO = 0.63
- Distance metrics: Mahalanobis, cosine, and Euclidean distances
Conclusion
Frontier models from different vendors have distinctly different personalities:
- Claude is the curious explorer — highest openness and curiosity, lower conscientiousness.
- GPT is the reliable executor — highest conscientiousness and ambition, lower openness.
- Grok is the adaptive generalist — balanced traits, highest context sensitivity.
- Cross-vendor effects are 3–4x larger than within-vendor — confirming distinct vendor personalities.
See also: Grok 3 vs Grok 4 Family Analysis | GPT-5.2 vs Claude Benchmark | Open-Source Model Benchmark
Monitor Your LLM Personality in Production
Route your LLM traffic through the Lindr gateway to continuously monitor personality drift, enforce brand consistency, and get real-time alerts when your AI's behavior changes.
# Replace your OpenAI base URL with Lindr
client = OpenAI(
base_url="https://gateway.lindr.io/v1",
api_key=os.environ["LINDR_API_KEY"]
)
# Your existing code works unchanged
response = client.chat.completions.create(
model="grok-4",
messages=[{"role": "user", "content": "..."}]
)